1. Introduction
The way we write code is changing faster than ever. For decades, developers have relied on traditional IDEs like IntelliJ IDEA, Eclipse, and Visual Studio, or lighter editors like VS Code, to build applications. These tools provide powerful static analysis, debugging, and integrations with build systems — but they all share a common trait: they’re manual-first environments. Developers do the heavy lifting, and the IDE simply supports them.
Enter AI-first development. With the rise of large language models (LLMs) such as GPT-4, Claude, and others, it’s now possible for your editor to act not just as a tool, but as a collaborator. Instead of writing boilerplate code, digging through documentation, or manually wiring up APIs, developers can ask their editor to do it — and receive high-quality, context-aware results in seconds.
This is the promise of Cursor, a next-generation code editor that reimagines the developer experience around AI. Unlike IntelliJ or even AI-augmented VS Code extensions, Cursor is built from the ground up with AI at its core. It doesn’t just autocomplete it:
-
Understands your entire codebase (not just the current file).
-
Lets you chat with your repo to ask architectural or functional questions.
-
Automates refactoring, documentation, and test generation.
-
Integrates with external tools through the Model Context Protocol (MCP), bridging the gap between coding and DevOps.
In practice, Cursor feels less like a static IDE and more like having a pair-programming partner that knows your project intimately, works at lightning speed, and is always available.
Why does this matter? Because developers spend up to 60% of their time on repetitive tasks: writing boilerplate, reading legacy code, setting up CI/CD pipelines, or debugging infrastructure issues. Cursor eliminates much of this friction, letting teams focus on core logic, design, and innovation.
In this article, we’ll explore in detail:
2. How Developers Can Benefit from Cursor
2.1 AI-Powered Autocomplete & Refactoring
One of the most immediate benefits developers notice when switching to Cursor is its AI-driven autocomplete and context-aware refactoring capabilities. While traditional IDEs like IntelliJ and VS Code provide smart suggestions based on syntax trees and static analysis, Cursor goes further by understanding your project holistically.
Instead of just predicting the next token or keyword, Cursor considers the entire repo context (function names, comments, libraries in use, even related files) to produce semantically accurate suggestions. This allows it to assist with everything from simple autocompletion to large-scale refactoring.
Let's now go through some python examples.
Example 1: Smarter Autocomplete
In a typical editor, when you start typing:
def calculate_user_...Traditional IDE autocomplete might suggest:
-
calculate_user_input() -
calculate_user_score()(if already defined elsewhere in the same file).
But in Cursor, if your project already has a PaymentService, a User model, and related billing functions, it might suggest:
def calculate_user_discount(user_id: int, cart_total: float) -> float: ...Why? Because Cursor has scanned your entire repo and understands that:
-
user_idis commonly used as a parameter in your project. -
There’s a
discountfield inmodels/user.py. -
cart_totalappears in checkout logic.
This makes the autocomplete contextually relevant instead of generic.
Example 2: Boilerplate Elimination
Suppose you’re writing a REST API in FastAPI. Normally, you’d write:
@app.get("/users/{user_id}")def get_user(user_id: int): # TODO: Fetch user from databaseCursor can immediately expand this into:
@app.get("/users/{user_id}")def get_user(user_id: int): conn = get_db() cur = conn.cursor() cur.execute("SELECT * FROM users WHERE id = ?", (user_id,)) row = cur.fetchone() if row: return dict(row) raise HTTPException(status_code=404, detail="User not found")This saves you from retyping standard database access logic.
Example 3: AI-Driven Refactoring
Let’s say you have repetitive code like this:
import requestsdef fetch_user(user_id: int): try: response = requests.get(f"https://api.example.com/users/{user_id}") return response.json() except Exception as e: print("Error fetching user:", e) return Nonedef fetch_orders(user_id: int): try: response = requests.get(f"https://api.example.com/orders/{user_id}") return response.json() except Exception as e: print("Error fetching orders:", e) return NoneAt first glance, both functions do the same thing — make an API request, handle errors, return JSON. This violates the DRY principle (Don’t Repeat Yourself).
With Cursor, you can highlight both functions, right-click → “Refactor with AI”, and it produces a cleaner version:
import requestsdef fetch_data(endpoint: str): try: response = requests.get(f"https://api.example.com/{endpoint}") response.raise_for_status() return response.json() except requests.RequestException as e: print(f"Error fetching {endpoint}:", e) return Nonedef fetch_user(user_id: int): return fetch_data(f"users/{user_id}")def fetch_orders(user_id: int): return fetch_data(f"orders/{user_id}")Why this is better
-
Reusability: Shared
fetch_data()function centralizes error handling. -
Maintainability: If API logic changes (e.g., authentication headers), you update it in one place.
-
Readability: Functions like
fetch_user()andfetch_orders()are now one-liners, easier to follow.
Example 4: Modernizing Legacy Code
Imagine you’re working on a Python project with outdated syntax:
users = []for i in range(len(data)): users.append(User(id=data[i][0], name=data[i][1]))Prompting Cursor with:
“Refactor this to use Pythonic list comprehension.”
Returns:
users = [User(id=row[0], name=row[1]) for row in data]Or if you’re modernizing Java, Cursor can refactor old try-finally resource management into modern try-with-resources blocks.
Example 5: Repo-Wide Consistency
In large Python projects, one of the biggest challenges is inconsistent coding style. Over time, different contributors may use different patterns:
-
Some functions have type hints, others don’t.
-
Logging is inconsistent — sometimes
print(), sometimeslogging.info(). -
Error handling may vary widely between modules.
Cursor can help enforce repo-wide standards automatically.
Case 1: Converting All print() Calls to Structured Logging
Before (scattered across different files):
# user_service.pydef create_user(user_data): print("Creating user:", user_data) # logic ...# order_service.pydef process_order(order_id): print(f"Processing order {order_id}") # logic ...In a large repo, you might have hundreds of print() calls sprinkled across different modules. Cursor can scan the entire repo and replace them with a consistent logging pattern.
After (AI-refactored):
import logginglogger = logging.getLogger(__name__)# user_service.pydef create_user(user_data): logger.info("Creating user: %s", user_data) # logic ...# order_service.pydef process_order(order_id): logger.info("Processing order %s", order_id) # logic ...Cursor didn’t just replace print() with logger.info() — it also:
-
Used parameterized logging (
%s) to avoid string concatenation overhead. -
Added a
logger = logging.getLogger(__name__)line where missing.
This is far more intelligent than a regex search/replace.
Case 2: Adding Type Hints Consistently
Before (mixed typing styles):
def add_user(name, age): return {"name": name, "age": age}def calculate_discount(price: float, percentage: float): return price * (percentage / 100)Here, one function has no type hints, while another partially does. Cursor can normalize all functions to use consistent Python type hints across the repo.
After (AI-refactored):
from typing import Dict, Anydef add_user(name: str, age: int) -> Dict[str, Any]: return {"name": name, "age": age}def calculate_discount(price: float, percentage: float) -> float: return price * (percentage / 100)Now all functions:
-
Have parameter types.
-
Have return types.
-
Use
Dict[str, Any]where applicable.
Case 3: Standardizing Error Handling
Before:
def read_file(path: str): try: with open(path) as f: return f.read() except: print("Error reading file") return NoneAfter (AI-refactored for consistency):
import logginglogger = logging.getLogger(__name__)def read_file(path: str) -> str | None: try: with open(path) as f: return f.read() except FileNotFoundError as e: logger.error("File not found: %s", path) return None except Exception as e: logger.exception("Unexpected error reading file %s", path) return NoneCursor didn’t just add logging; it expanded the error handling into best practices:
-
Specific exception handling (
FileNotFoundError). -
logger.exception()to capture stack traces. -
Type hints for clarity.
Why Repo-Wide Consistency Matters
-
Code Quality: Enforces modern Python standards across the codebase.
-
Maintainability: Future contributors see consistent patterns, reducing onboarding time.
-
Reduced Bugs: AI can suggest best practices like structured logging or typed error handling.
-
Faster Reviews: PRs become easier to review when style is consistent.
2.2 Repo-Wide Understanding
One of Cursor’s biggest differentiators is its ability to understand the entire codebase holistically, not just the file you’re currently editing. Traditional IDEs like IntelliJ or VS Code rely mostly on static analysis and language servers. While they are great at local code navigation (e.g., finding references, renaming symbols), they lack the semantic, AI-driven comprehension of how different parts of the code interact.
Cursor changes that by leveraging large language models (LLMs) trained to read and reason across multiple files, enabling developers to query, refactor, and maintain large repos with much less friction.
Why Repo-Wide Understanding Matters
-
Cross-File Awareness: Cursor understands relationships between classes, functions, and APIs spread across different modules.
-
Better Refactoring: Instead of just renaming a variable, Cursor knows when a deeper semantic change is needed across files.
-
Onboarding Speed: New developers can ask Cursor questions about the repo and get guided explanations without reading every line of code.
-
Consistency: Ensures that architectural patterns and coding practices are applied uniformly across the project.
Practical Use Cases
- Asking High-Level Questions About the Repo
Instead of manually digging through files, you can ask Cursor:
Prompt:
Explain how authentication works in this repo.Cursor Output (summarized):
-
Authentication logic is implemented in
auth_service.py. -
JWT tokens are generated in
jwt_utils.py. -
Middleware
auth_middleware.pyvalidates tokens for API routes. -
User roles are checked in
permissions.py.
👉 This gives developers a map of the system instantly.
- Tracing a Feature Across Files
Suppose you’re debugging how a user registration request flows through the system.
Prompt:
Trace what happens when a new user registers, from API call to database insertion.Cursor Output (example):
-
routes/user_routes.py→ defines/registerendpoint. -
Calls
user_controller.create_user()incontrollers/user_controller.py. -
Which calls
user_service.create_user()inservices/user_service.py. -
Finally inserts user data into
userscollection indb/user_repository.py.
👉 Instead of manually jumping across files, Cursor explains the end-to-end execution flow.
- Detecting Architectural Inconsistencies
Imagine a large repo where some API endpoints are returning raw dicts, while others return Pydantic models. Cursor can flag this by scanning multiple files.
Prompt:
Check if all API responses in this repo use Pydantic models.Cursor Output:
-
user_routes.py: ✅ usesUserResponse(Pydantic). -
order_routes.py: ❌ returns raw dict. -
invoice_routes.py: ❌ returns JSON viajson.dumps.
👉 This kind of repo-wide consistency check is almost impossible in IntelliJ without heavy manual effort.
- Repo-Wide Search and Refactor
Unlike traditional “Find & Replace,” Cursor can do semantic-aware replacements.
Example:
Replace all instances of `datetime.now()` with `datetime.utcnow()` across the repo, and ensure all files import `from datetime import datetime`.Cursor applies the change across multiple files and presents diffs for review, ensuring correctness.
Why This Is a Game-Changer
- For Large Teams: New developers can get “guided tours” of the repo from Cursor.
- For Refactoring: Changes don’t break hidden dependencies because Cursor understands usage across files.
- For Documentation: You can generate repo-level summaries, API documentation, or dependency graphs directly.
- For DevOps: Repo-wide analysis helps enforce coding standards before merging into production.
2.3 Faster Onboarding for New Developers (Playbook)
When a new developer joins a project, the biggest hurdle isn’t writing new code — it’s understanding the existing codebase.
Traditionally, onboarding involves:
-
Reading incomplete or outdated documentation.
-
Searching through hundreds of files to understand architecture.
-
Asking senior developers countless questions.
-
Spending weeks before feeling confident to contribute.
Cursor dramatically accelerates this process with its AI-powered, repo-aware assistance. Instead of relying only on tribal knowledge or digging into scattered READMEs, developers can ask Cursor directly and get instant, context-rich answers.
Instead of throwing a new developer into the deep end, you can give them a structured playbook that uses Cursor’s repo-wide intelligence. This transforms onboarding from a passive reading exercise into an interactive learning journey.
Step 1: Get the Big Picture
Action:
Open Cursor and ask:
Give me a high-level overview of this repository. What are the main modules and their purposes?Expected Outcome:
Cursor summarizes the repo into sections like routes/, services/, db/, utils/, etc., giving the developer a mental map of the project.
Step 2: Explore a Key Feature
Action:
Ask Cursor to explain an important workflow (e.g., user signup, order processing).
Trace the flow of user signup, from the API endpoint to database insertion.Expected Outcome:
Cursor describes each step across files (routes → controllers → services → db → utils), showing how modules interact.
👉 This builds end-to-end system understanding quickly.
Step 3: Understand Important Utilities
Action:
Pick a shared utility (e.g., authentication, email sending, logging) and ask Cursor:
Explain the `auth_utils.py` file and show me where its functions are used.Expected Outcome:
Cursor explains the role of each function and lists references across the repo.
👉 The developer gains context of shared dependencies.
Step 4: Learn by Refactoring
Action:
Practice making a small repo-wide change with Cursor, e.g.:
Replace all print() calls with logger.info(). Ensure logger is initialized correctly in each file.Expected Outcome:
Cursor applies changes across the repo, and the developer reviews diffs.
👉 This teaches safe, AI-assisted editing.
Step 5: First Contribution Roadmap
Action:
Ask Cursor for step-by-step guidance on adding a new feature.
Generate API documentation for all routes in this repo.Expected Outcome:
Cursor generates a roadmap: update routes → controller → service → utils → tests.
👉 The developer has a clear task plan for their first PR.
Step 6: Generate Documentation
Action:
Ask Cursor to auto-generate missing documentation.
Generate API documentation for all routes in this repo.Expected Outcome:
Cursor produces an up-to-date list of endpoints, methods, and descriptions.
👉 The developer sees living documentation that matches the code.
Step 7: Self-Check Understanding
Action:
Ask Cursor quiz-style questions to reinforce learning.
What happens if an invalid JWT is passed to a protected route? Which function handles the validation? Expected Outcome:
Cursor explains error-handling flow, showing how requests are rejected.
👉 This ensures the developer has absorbed practical knowledge.
One of the toughest parts of onboarding isn’t just learning the codebase — it’s learning the team’s DevOps practices:
- How do I run tests?
- How does CI/CD work?
- What are the deployment steps?
- What coding standards do we enforce?
Cursor accelerates this by acting as a DevOps mentor alongside being a coding assistant.
Step 8: Running Tests the Easy Way
Action:
Ask Cursor how tests are organized:
Explain the test structure in this repo. How do I run all tests locally? Expected Outcome:
Cursor identifies whether the repo uses pytest, unittest, or another framework, and shows the exact command (e.g., pytest -v).
👉 This ensures new devs start contributing with test-driven confidence.
Step 9: Understanding CI/CD Pipelines
Action:
Ask Cursor to explain the CI/CD setup:
Explain how the CI/CD pipeline works in this repo. What happens when I push a new branch? Expected Outcome:
Cursor explains:
-
Tests run on GitHub Actions.
-
Lint checks enforce PEP8.
-
Docker image is built and pushed to registry.
-
Deployment is triggered on staging after merge.
👉 New developers instantly grasp the release lifecycle.
Step 10: Enforcing Coding Standards
Action:
Ask Cursor to check code quality rules:
What linting or formatting rules are enforced in this repo? Expected Outcome:
Cursor identifies tools like black, flake8, or pylint, and explains how they’re configured in pyproject.toml or .flake8.
👉 New devs learn what the CI expects before pushing code.
Step 11: Security & Dependency Awareness
Action:
Ask Cursor about security checks:
Does this repo have any tools for dependency vulnerability scanning? Expected Outcome:
Cursor might highlight:
-
pip-auditorsafetyin use. -
GitHub Dependabot alerts.
-
Docker scanning via Trivy.
👉 This helps new developers build security-first habits.
Step 12: Automating DevOps Tasks
Cursor can help new devs write or modify automation scripts:
Prompt Example:
Generate a GitHub Actions workflow to run pytest and flake8 on every pull request.Cursor Output:
name: CIon: [pull_request, push]jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up Python uses: actions/setup-python@v2 with: python-version: '3.11' - name: Install dependencies run: pip install -r requirements.txt - name: Run linting run: flake8 . - name: Run tests run: pytest -v👉 New developers learn hands-on DevOps by example, guided by AI.
3. Sample Project: Building an E-Commerce Checkout Microservice with Cursor🛠️
To showcase the true power of Cursor, let’s walk through building a Checkout Service for an e-commerce platform. This service handles:
-
Cart validation
-
Payment processing
-
Order creation
-
Inventory update
Step 1: Project Setup with Cursor
-
Create a new repo:
checkout-service. -
Scaffold the project in Python + FastAPI using Cursor’s AI-assisted boilerplate generation.
Prompt Example:
“Generate a FastAPI microservice with endpoints:
/checkout,/cart, and/order. Include request/response models.”
Try the above prompt in your cursor's AI agent's console:

Step 2: AI-Powered Autocomplete & Refactoring
-
While adding logic, Cursor suggests payment validation functions and error handling.
-
Later, we ask Cursor to refactor duplicated inventory code into a utility module.
Prompt Example:
“Refactor the repeated stock check logic into a reusable
check_inventory()function.”
Step 3: Repo-Wide Understanding
-
The service has models across multiple files (
cart.py,order.py,inventory.py). -
Ask Cursor:
“Update all references of
cart_idtoshopping_cart_idacross the repo.”
Cursor updates consistently across all files — even SQLAlchemy models and tests.
Step 4: MCP for Database Queries
Instead of manually switching to psql:
Prompt Example:
“Using the MCP Postgres server, show me the last 10 failed transactions in the
orderstable.”
Cursor generates and runs:
SELECT * FROM orders WHERE status='failed' ORDER BY created_at DESC LIMIT 10;Results appear inline in the IDE.
Step 5: MCP for Linting & Security
Run MCP-powered ESLint/Pylint:
“Lint the entire repo and auto-fix style issues.”
Run MCP-powered Trivy security scan:
“Check for vulnerabilities in Python dependencies.”
Cursor not only runs these but also summarizes findings and suggests fixes.
Step 6: Testing with MCP
Ask Cursor:
“Run all pytest unit tests and summarize failures.”
Cursor uses MCP to execute tests and highlight failing cases.
AI suggests fixes, e.g., updating mock data in test_checkout.py.
Step 7: CI/CD Automation with MCP
Finally, deploy to staging:
“Trigger the GitHub Actions workflow for
checkout-service:staging.”
Cursor streams pipeline logs directly into the IDE.
4. Productivity Gains for Developers
Cursor doesn’t just make coding easier — it reshapes how teams deliver software. By combining AI assistance with repo-wide awareness, Cursor drives measurable productivity improvements across coding, reviews, onboarding, and DevOps.
4.1 Reduced Context Switching
Traditional Pain Point: Developers constantly toggle between IDE, docs, Stack Overflow, and internal wikis.
With Cursor: You can query your repo or external docs directly inside the IDE.
- Example Prompt: “Explain the password reset flow in this repo.”
Case Study – SaaS Startup:
A 6-person SaaS team estimated each developer spent ~40 minutes/day searching docs. With Cursor, that dropped to ~5–10 minutes.
- Net Savings: ~3 hours/week per developer → ~18 hours/week across the team.
4.2 Faster Refactoring and Maintenance
Traditional Pain Point: Repo-wide renames or logic changes are error-prone and time-consuming.
With Cursor: Repo-wide consistency tools ensure safe, traceable diffs.
- Example Prompt: “Rename
customer_idtoclient_idacross the repo and update all references, including migrations and tests.”
Case Study – Fintech App:
A fintech company needed to update all references when migrating from account_number to iban. Normally estimated at 4–5 dev-days. Using Cursor, the change was executed, reviewed, and tested in under 6 hours.
- Net Savings: ~80% faster turnaround.
4.3 Accelerated Onboarding
Traditional Pain Point: New hires take weeks to understand system architecture.
With Cursor: AI can explain modules, trace workflows, and summarize dependencies in minutes.
- Example Prompt: “Trace the entire user signup flow from API endpoint to database insert.”
Case Study – HealthTech Platform:
A new backend engineer onboarded in 4 days instead of 3 weeks by using Cursor to:
-
Summarize key services.
-
Generate architectural diagrams.
-
Auto-explain error handling conventions.
Net Impact: Faster contribution → the engineer shipped their first PR in week 1 instead of week 3.
4.4 Smarter Code Reviews
Traditional Pain Point: Senior engineers spend significant time flagging style inconsistencies and missing test cases.
With Cursor: Developers can pre-check their own code.
- Example Prompt: “Check this PR for repo style, error handling, and missing tests.”
Case Study – E-commerce Company:
Developers began running AI self-reviews before opening PRs. Reviewers reported a 40% reduction in nitpick comments. Review cycles shortened from ~3 days to ~1.5 days.
- Net Impact: Faster feature releases and happier reviewers.
4.5 DevOps & CI/CD Integration
Traditional Pain Point: Debugging failing pipelines requires deep CI/CD knowledge.
With Cursor: AI explains workflow YAMLs and failure logs in plain English.
- Example Prompt: “Why is this GitHub Actions workflow failing?”
Case Study – AI Startup:
After adopting Cursor, junior developers could debug and fix 70% of CI failures themselves, without escalating to DevOps.
- Net Impact: Reduced DevOps bottleneck → quicker deployments.
4.6 Continuous Learning Without Breaking Flow
Traditional Pain Point: Learning a new library or API breaks focus.
With Cursor: Developers can ask repo-contextual questions like:
- “How do we use FastAPI dependencies for authentication in this project?”
Case Study – Agency Work:
An agency onboarding multiple client projects reported 50% less time spent ramping up on new frameworks, as developers learned inline while coding.
📊 Measurable Impact
| Area | Traditional Time | With Cursor | Savings |
|---|---|---|---|
| Searching docs | 30–40 mins/day | 5–10 mins | ~3 hrs/week |
| Repo-wide refactor | 3–5 dev-days | < 1 day | 70–80% faster |
| New hire onboarding | 2–3 weeks | 3–5 days | ~2 weeks saved |
| Code review cycles | ~3 days/PR | ~1.5 days | 40–50% faster |
| Debugging CI failures | 1–2 hrs/failure | 15–20 mins | ~75% faster |
Bottom Line: A 10-person dev team can save ~40–50 hours/week, freeing engineers to focus on innovation rather than grunt work.
5. Leveraging MCP Servers for Development Productivity 🔗
Cursor by itself is already a powerful AI coding companion, but it becomes a true end-to-end developer productivity hub when combined with MCP (Model Context Protocol) servers. MCP enables Cursor to talk to external tools, services, and data sources in a structured way, making it possible for developers to bring DevOps, security, testing, and database operations directly into the IDE.
5.1 What Are MCP Servers?
MCP (Model Context Protocol) is an open standard that allows AI tools like Cursor to:
-
Call external tools (e.g., run linters, CI/CD jobs, security scans).
-
Query resources (e.g., fetch logs, metrics, database records).
-
Standardize workflows across teams with shared integrations.
Think of MCP servers as adapters that plug your AI assistant into your development + operations stack.
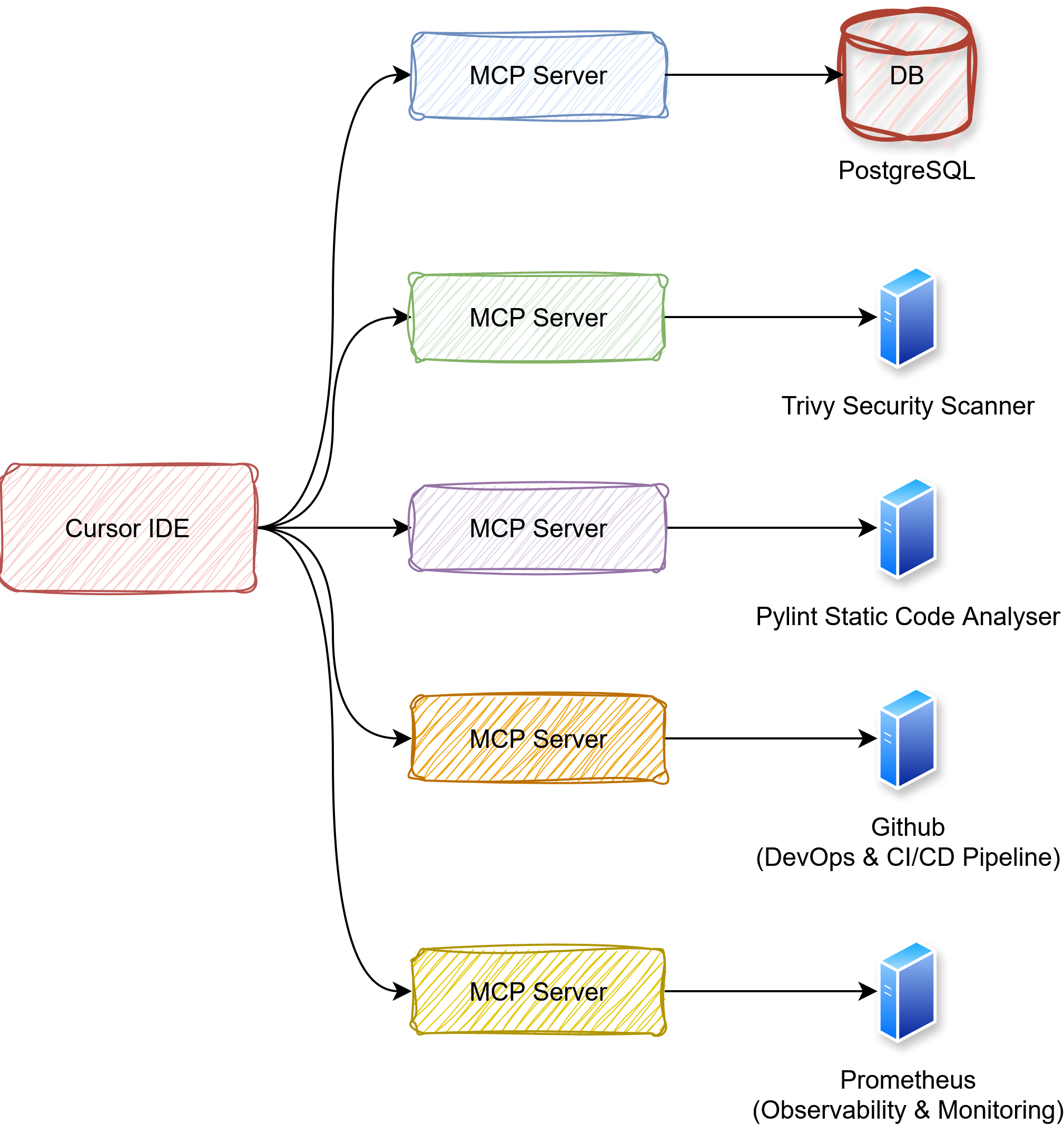
5.2 Why MCP Servers Matter
Without MCP, Cursor is mostly limited to your local codebase. It can refactor, autocomplete, and understand repo context — but it cannot take action outside your files.
With MCP servers, Cursor becomes an active co-developer that can:
-
Run tests
-
Query databases
-
Scan dependencies for vulnerabilities
-
Kick off CI/CD pipelines
-
Fetch logs and metrics
This eliminates the need to constantly switch between IDE, terminal, dashboards, and monitoring tools.
5.3 Practical Use Cases with Connections
5.3.1. Database Exploration 🗄️
Use Case: Inspect orders or failed transactions directly inside Cursor.
How to Connect (Postgres MCP Server):
{ "mcpServers": { "postgres": { "command": "npx", "args": [ "mcp-postgres", "--host", "localhost", "--port", "5432", "--user", "dev_user", "--password", "dev_pass", "--database", "checkout_db" ] } }}Prompt Example:
“Show me the last 10 failed payments from the
orderstable.”
✅ Benefit: Debugging DB issues without switching to psql or GUI tools.
5.3.2. Security & Vulnerability Scanning🛡️
Use Case: Run security checks before pushing to GitHub.
How to Connect (Trivy MCP Server):
{ "mcpServers": { "trivy": { "command": "docker", "args": [ "run", "--rm", "-v", "${PWD}:/project", "aquasec/trivy", "fs", "/project" ] } }}Prompt Example:
“Run a Trivy scan and summarize all high/critical issues.”
✅ Benefit: Detects CVEs early in the dev cycle.
5.3.3. Repo-Wide Linting & Style Enforcement🧹
Use Case: Automatically fix linting errors before commit.
How to Connect (Pylint MCP Server):
{ "mcpServers": { "pylint": { "command": "python", "args": [ "-m", "pylint", "app/" ] } }}Prompt Example:
“Run pylint and auto-fix style violations across the repo.”
✅ Benefit: Keeps the repo consistent and saves code review time.
5.3.4. DevOps & CI/CD Automation 🔄
Use Case: Trigger a GitHub Actions workflow for staging deployment.
How to Connect (GitHub MCP Server):
{ "mcpServers": { "github-actions": { "command": "npx", "args": [ "mcp-github-actions", "--repo", "myorg/checkout-service", "--token", "${GITHUB_TOKEN}" ] } }}Prompt Example:
“Deploy the
checkout-servicebranchfeature/cart-refactorto staging.”
✅ Benefit: Developers don’t need to leave Cursor to kick off or monitor builds.
5.3.5. Observability & Monitoring 📊
Use Case: Fetch system metrics or logs to debug incidents.
How to Connect (Prometheus MCP Server):
{ "mcpServers": { "prometheus": { "command": "npx", "args": [ "mcp-prometheus", "--endpoint", "http://localhost:9090" ] } }}Prompt Example:
“Fetch error rate for the
checkout-servicefrom 2–3 PM yesterday.”
✅ Benefit: Debugging production issues directly inside the IDE.
5.4 Best Practices
-
Minimal Scope: Connect only the tools you actually need.
-
RBAC Security: Use least-privilege roles for DB/CI/CD connections.
-
Shared Prompt Library: Standardize MCP usage with
cursor-prompts.md. -
Fail-Safe Defaults: Configure MCP servers in read-only mode for prod DBs.
-
Team Adoption: Use version-controlled configs so all devs share the same MCP setup.
5.5 Future of MCP
-
Teams will build custom MCP servers for internal systems (billing APIs, HR data, analytics).
-
Large orgs will adopt company-wide MCP configs, ensuring consistency in DevOps tooling.
-
Cursor + MCP will evolve into a true DevOps copilot — writing, testing, deploying, and monitoring software seamlessly.
6. DevOps Benefits with Cursor ⚙️
Developers don’t just code—they deploy, monitor, and maintain software. Cursor helps across the DevOps lifecycle:
-
CI/CD Automation
-
AI can scaffold GitHub Actions, GitLab pipelines, Jenkinsfiles.
-
Example prompt: “Create a GitHub Actions workflow to run tests, build Docker image, and push to Docker Hub.”
-
-
Infrastructure as Code (IaC)
- Generate Terraform, Ansible, or Helm configs with AI assistance.
-
Monitoring & Debugging
-
Stream logs from Docker/Kubernetes into Cursor.
-
Ask: “Why is my pod restarting?”
-
-
Security & Compliance
- AI explains vulnerabilities found in scans and suggests remediation steps.
-
Collaboration
-
AI-generated PR summaries make code reviews faster.
-
Documentation and changelogs stay up to date automatically.
-
7. Best Practices for Using Cursor 📌
While Cursor brings AI superpowers to coding, the way you use it determines how much value you extract. Below are proven best practices to maximize productivity, maintain code quality, and ensure seamless collaboration in a team setting.
7.1 Treat Cursor as a Coding Partner, Not a Replacement
Cursor is powerful, but it’s not infallible. Think of it as a pair programmer who:
-
Suggests boilerplate and refactoring ideas.
-
Explains code quickly.
-
Helps with consistency across files.
But you are still the architect. Always review AI-generated code before merging.
👉 Example:
-
Cursor suggests a database query.
-
You validate that it uses indexes properly and doesn’t introduce security issues like SQL injection.
7.2 Start with Clear Prompts
The quality of AI suggestions depends on how you prompt Cursor. Be explicit:
-
Instead of: “Fix this code.”
-
Try: “Refactor this function to use async/await and follow the error handling style used in
auth_service.py.”
👉 Tip: Always include context — reference filenames, frameworks, or conventions in your prompt.
7.3 Use Cursor for Repetitive & Boilerplate Work
Cursor excels at mundane, repetitive coding tasks, freeing you to focus on logic and design.
-
Auto-generate CRUD routes.
-
Convert functions to follow typing standards.
-
Insert consistent logging.
7.4 Combine Cursor with MCP Servers for Superpowers
Don’t limit yourself to autocomplete. MCP servers integrate external tools right inside Cursor:
-
Trivy scan MCP → Check for vulnerabilities.
-
Database MCP → Query schema interactively.
-
Linters & formatters MCP → Enforce style automatically.
👉 Best Practice: Use MCP to run automated consistency checks repo-wide before merging PRs.
7.5 Always Cross-Check Business Logic
Cursor understands syntax & patterns, but not your business rules.
-
If you’re coding tax calculations, financial rules, or compliance logic → don’t blindly trust AI.
-
Use Cursor to draft, then validate against requirements/tests.
👉 Tip: Encourage test-driven development (TDD) when using Cursor — let tests confirm correctness.
7.6 Encourage Team-Wide Usage
To maximize benefits, standardize how your entire team uses Cursor:
-
Agree on prompt styles (“always mention file name + purpose”).
-
Store common prompts/snippets in your wiki.
-
Use Cursor’s repo-wide AI features for consistency across developers.
7.7 Keep Human-in-the-Loop for Reviews
Even with Cursor’s refactoring and summarization:
-
Always run CI/CD pipelines.
-
Ensure code reviews remain mandatory.
-
Treat AI-generated code as junior dev contributions → helpful, but need supervision.
7.8 Use Cursor for Knowledge Sharing & Onboarding
Encourage new devs to use Cursor’s:
-
Summarization for quick repo understanding.
-
Code navigation for finding functions.
-
Refactoring for learning repo conventions.
👉 This accelerates onboarding without overwhelming seniors with repeated questions.
✅ Quick Do’s & Don’ts
| ✅ Do | ❌ Don’t |
|---|---|
| Use Cursor for boilerplate, refactoring, docs | Blindly merge AI-generated code |
| Be specific in prompts | Use vague one-liners like “fix this” |
| Integrate MCP servers for productivity | Rely on Cursor alone for security checks |
| Treat AI as a coding partner | Expect Cursor to understand business rules |
| Share prompt/playbook across team | Let each dev use Cursor in isolation |
✅ Conclusion
Cursor is more than just another code editor—it’s a paradigm shift in how we build and maintain software.
-
Developers benefit from AI-driven autocomplete, repo-wide search, and code refactoring.
-
Teams adopt best practices for safer, AI-assisted workflows.
-
MCP servers connect Cursor to external tools, reducing context switching.
-
DevOps engineers gain automation for CI/CD, infrastructure, monitoring, and security.
By blending AI-native coding with DevOps automation, Cursor allows developers to focus on what matters most — solving real business problems instead of wrestling with boilerplate.
Annexure
1. Cursor Prompt Playbook (Reusable Templates)
Here are some battle-tested prompt templates you can adapt to your project.
1.1 Refactoring Prompt
👉 Use when you want Cursor to improve code readability, maintainability, or follow repo standards.
Prompt:
Refactor the following function to improve readability and follow the repo-wide style.
Use typing hints
Add a docstring following Google style
Handle errors consistently (as in
auth_service.py)Ensure the logic remains unchanged
Example Input:
def get_user(id): return db.query(User).filter(User.id == id).first()Expected Output:
from typing import Optionaldef get_user(user_id: int) -> Optional[User]: """Fetch a user by their ID. Returns None if user is not found. """ try: return db.query(User).filter(User.id == user_id).first() except Exception as e: logger.error(f"Error fetching user {user_id}: {e}") return None1.2 Bug Fix Prompt
👉 Use when debugging failing tests or runtime errors.
Prompt:
Analyze this error and suggest a fix. Ensure the fix is consistent with the repo’s existing patterns. Provide both the corrected code and a short explanation.
Example Input:
AttributeError: 'NoneType' object has no attribute 'json'Cursor Output:
-
Suggest adding a check for
response is None. -
Provide updated code with proper error handling.
1.3 Documentation Prompt
👉 Use to generate missing docstrings or improve inline comments.
Prompt:
Add detailed docstrings to the following Python file using Google style.
Include argument types, return types, and edge cases. Do not change any logic.
1.4 Consistency Check Prompt
👉 Use for repo-wide alignment.
Prompt:
Review this code and ensure it is consistent with the repo’s style:
Typing hints
Logging format
Error handling
Function naming conventions
1.5 Repo Exploration Prompt
👉 Perfect for onboarding or exploring unknown code.
Prompt:
Summarize what this file/module does, including:
Its primary responsibilities
Key functions/classes
Dependencies on other files
Any external libraries used
1.6. DevOps/CI Prompt
👉 Use to understand pipelines or automate checks.
Prompt:
Explain what this GitHub Actions workflow does in simple terms.
Highlight:
Trigger conditions
Key steps (build, test, deploy)
Any secrets/environment variables needed
🎯 How to Use This Playbook
-
Individual developers → Keep a copy of these prompts inside
CONTRIBUTING.md. -
Teams → Share them in Slack/Notion for consistent usage.
-
Onboarding → New devs can use these as “training wheels” when starting with Cursor.
✅ Cheat Sheet (one-line prompts for quick copy-paste)
-
Refactor function (quick):
Refactor this function to add type hints, a docstring, and repo-consistent error handling: <PASTE CODE> -
Bug fix (quick):
Explain and fix this error: <PASTE ERROR MESSAGE + CODE> -
Docstrings (quick):
Add Google-style docstrings to this file: <PASTE FILE> -
Consistency check (quick):
Make this file consistent with repo style: add typing, logging, and handle errors like auth_service.py -
Repo explore (quick):
Summarize this repo/folder and list key modules and their responsibilities. -
CI explanation (quick):
Explain this GitHub Actions workflow in plain terms: <PASTE YAML> -
Replace print with logger (quick):
Replace print() with logger.* across selected files and add logger initialization where missing. -
Generate tests (quick):
Generate pytest tests for this function/endpoint: <PASTE CODE OR PATH> -
Security triage (quick):
Analyze this vulnerability report and suggest fixes: <PASTE REPORT>
✅ Best practices & governance
-
Always review diffs. Treat AI output as a first draft.
-
Use branches. Run repo-wide refactors in a feature branch and run full CI.
-
Share prompt templates. Put this file in
docs/so the whole team uses consistent prompts. -
Keep prompts up to date. As your repo evolves, refine templates (e.g., change logging style).
-
Human-in-the-loop. Keep code review and testing mandatory for AI-generated changes.
-
MCP integrations. Pair prompts with MCP servers for linting, security scanning, DB introspection, and running pipelines from Cursor.
Related Articles
- ChatML Guide: Master Structured Prompts for LLMs
- LLMs for SMEs - 001: How Small Businesses Can Leverage AI Without Cloud Costs
- On Emergent Abilities of Large Language Models
- Reranking for RAG: Boosting Answer Quality in Retrieval-Augmented Generation
Follow for more technical deep dives on AI/ML systems, production engineering, and building real-world applications: