1. Introduction
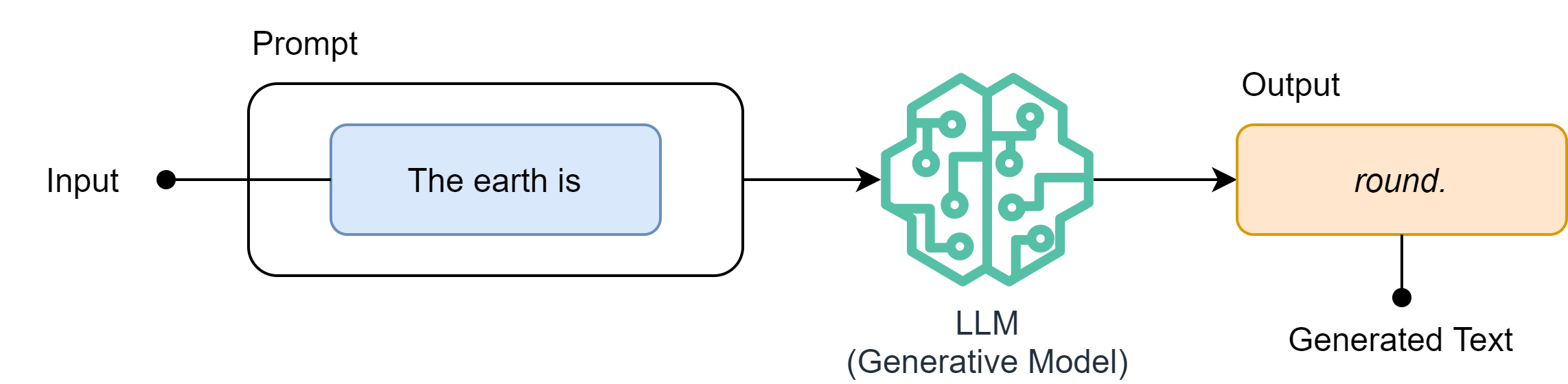
Prompt engineering is the practice of designing and refining the text (prompt) that we pass to a Generative AI (GenAI) model. The prompt acts as an instruction or query, and the model generates responses based on it. Prompts can be questions, statements, or detailed instructions.
Prompt engineering serves three purposes:
-
Enhancing output quality – refining how the model responds.
-
Evaluating model behavior – testing the output against requirements.
-
Ensuring safety – reducing harmful or biased responses.
There is no single “perfect” prompt. Instead, prompt design is an iterative process involving optimization and experimentation.
2. Controlling Model Output by Adjusting Model Parameters
The behavior of large language models (LLMs) can be fine-tuned using parameters such as temperature, top_p, and top_k. For these to take effect, do_sample=True must be set, allowing the model to sample tokens instead of always choosing the most likely one.
-
Temperature controls randomness.
-
temperature=0: deterministic output (always the same response). -
Higher values → more diverse responses.
-
Example:
0.2= focused, coherent;0.8= more creative.
-
-
Top_p (nucleus sampling) restricts token choices to the smallest set whose cumulative probability ≥ p.
-
top_p=1: consider all tokens. -
Lower values → more focused output.
-
-
Top_k limits the selection to the k most likely tokens.
By tuning these, one can strike a balance between deterministic/focused and creative/diverse outputs.
3. Instruction-Based Prompting
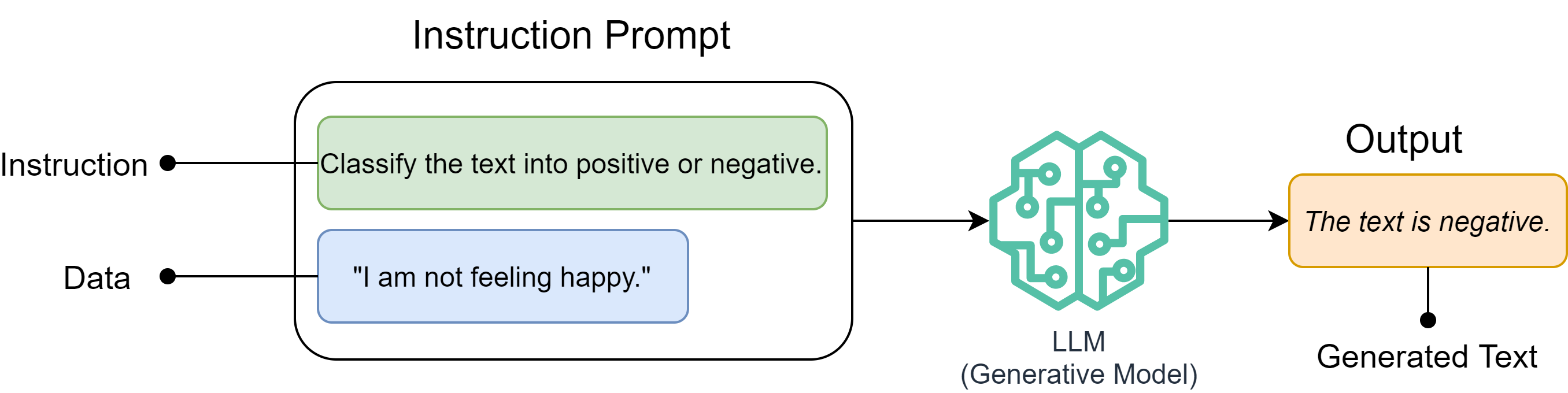
Instruction-based prompting is one of the most fundamental and widely used approaches in working with large language models (LLMs). It involves providing the model with explicit, structured, and unambiguous instructions that guide how the response should be generated.
At its core, an instruction-based prompt consists of two essential components:
-
Instruction – what the model is supposed to do (e.g., “Summarize the text in one sentence.”).
-
Data – the input on which the instruction operates (e.g., the paragraph to be summarized).
A simple example:
Prompt
Instruction: """Summarize the following text in one sentence. Data: Artificial Intelligence is revolutionizing industries such as healthcare, finance, and education by automating tasks and enabling data-driven decision-making. """Output
AI is transforming industries by automating tasks and enabling smarter decisions. The following diagram depicts a basic instruction prompt. Please note the instructions and data in the prompt.
3.1 Adding Output Indicators
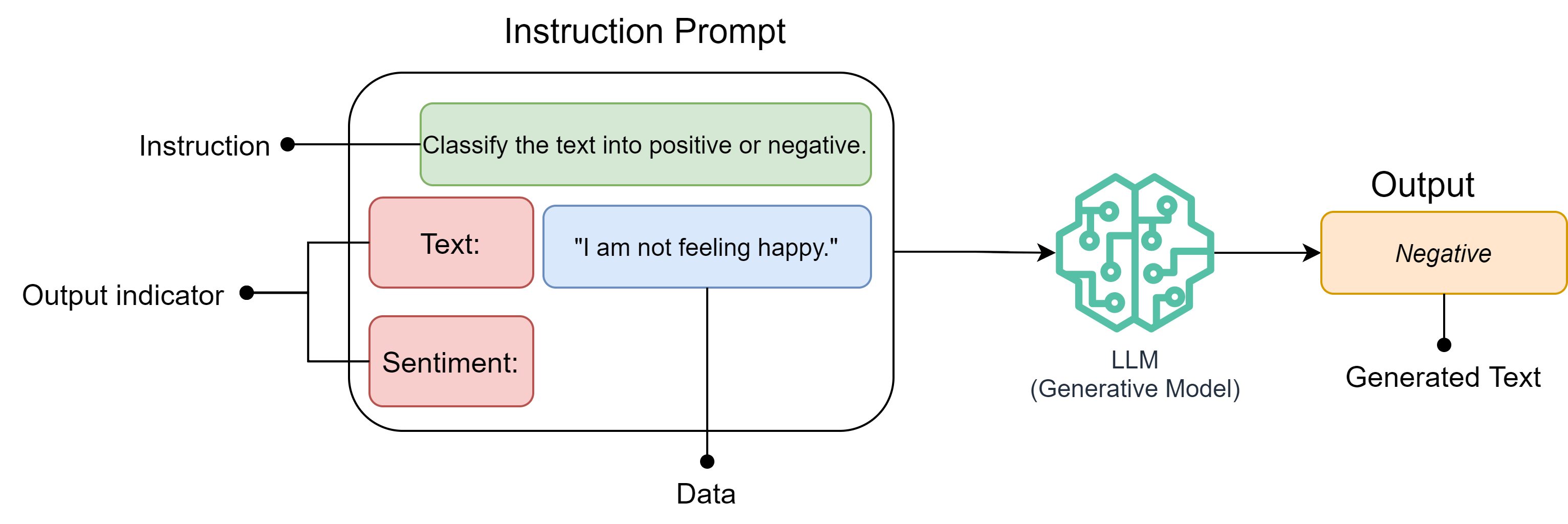
Sometimes instructions alone are not enough. To make the response more constrained and predictable, we can add output indicators – predefined answer formats or expected categories.
For example:
Prompt
Instruction: Classify the sentiment of the following review. Data: “The product is amazing and works perfectly.” Output options: Positive | Negative Output
Positive The following diagram depicts the instruction prompt with an output indicator.
3.2 Task-Specific Prompt Formats
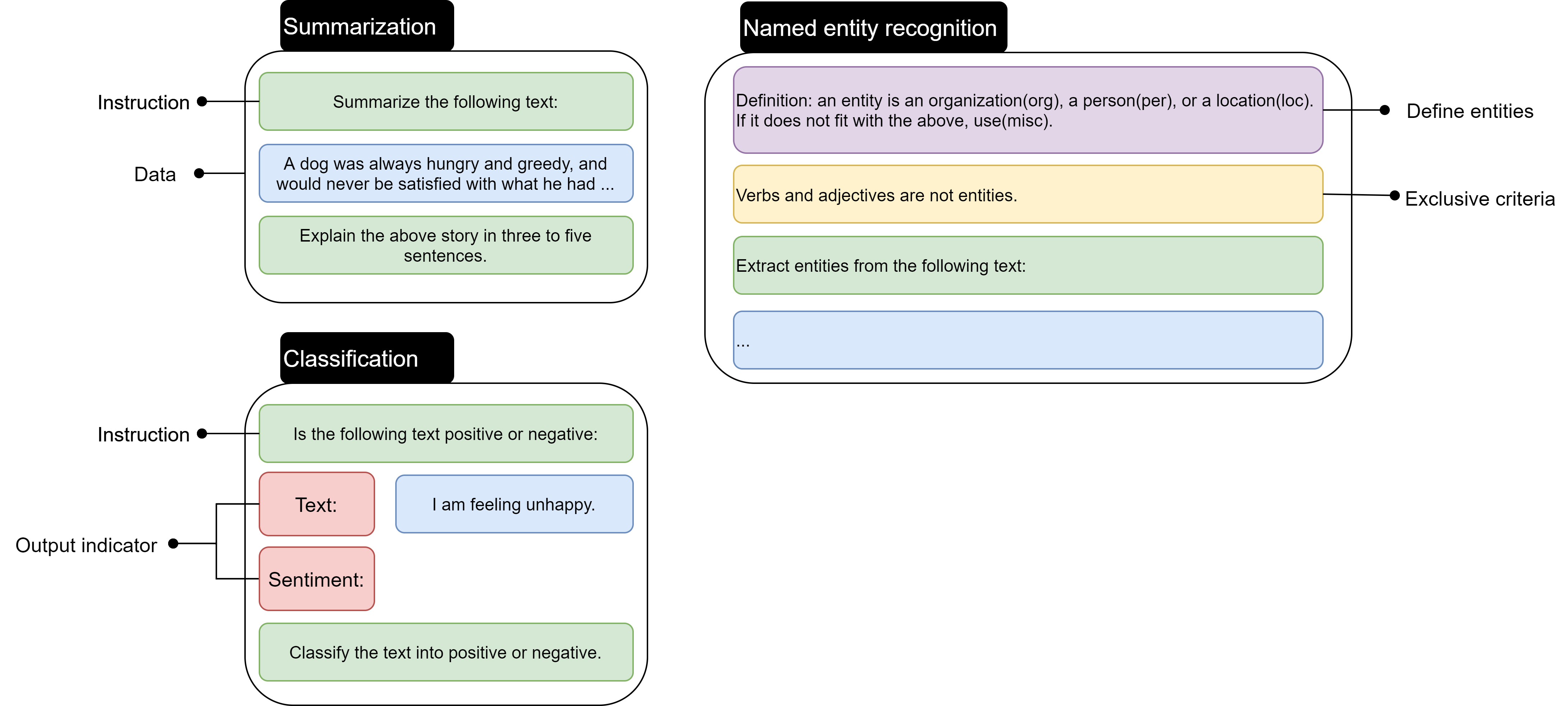
Different NLP tasks require slightly different instruction structures. For example:
-
Summarization: “Summarize the following paragraph in 2–3 sentences.”
-
Classification: “Classify the following text as spam or not spam.”
-
Named Entity Recognition (NER): “Extract all names of organizations mentioned in the following text and list them as a JSON array.”
These formats not only help the model but also make evaluation easier for humans.
The following diagram illustrates example formats for summarization, classification, and named-entity recognition.
3.3 Prompting Techniques for Better Results
Instruction-based prompting can be improved using several best practices:
-
Specificity
Be as precise as possible. Instead of “Explain photosynthesis”, say “Explain photosynthesis in 3 simple steps, suitable for a 10-year-old student.” -
Hallucination Control
LLMs sometimes generate plausible but false answers (hallucinations). To mitigate this, include safeguards:
If you are not sure about the answer, respond with: "I don't know." -
Order Matters (Primacy and Recency Effects)
LLMs pay more attention to the beginning and end of a prompt. Place the most important instructions either at the start or the end to maximize compliance.
3.4 Beyond the Basics: Modular Prompt Components
While instruction, data, and output indicators are the core building blocks, prompts can be made more modular and adaptive by incorporating additional components such as:
-
Personalization – “You are a financial advisor…”
-
Instruction – “Summarize, compare, explain…”
-
Context – background information that helps the model.
-
Format – JSON, table, bullet points, plain text.
-
Audience – “Explain as if to a high school student.”
-
Tone – formal, casual, persuasive, neutral.
-
Data – the actual input for the model to process.
This modularity makes prompts flexible. You can add or remove components depending on the use case, and observe how the output changes.
The following is an example that uses the above prompt components. This example demonstrates the modular nature of prompting. We can experiment by adding or removing components to see the effect.

3.5 Example: Modular Prompt
Prompt
Personalization: You are a career coach. Instruction: Provide advice on writing a resume. Context: The user is applying for a software engineering role at a mid-sized startup. Format: List your advice as 5 bullet points. Audience: Entry-level job seeker with 1 year of internship experience. Tone: Encouraging and practical. Data: “How should I improve my resume?” Output
1. Highlight your technical skills (Python, JavaScript, databases). 2. Add details about your internship projects—focus on impact. 3. Tailor your resume to the startup by showing adaptability and problem-solving. 4. Keep the format clean, concise, and one page. 5. Add a short section for personal projects or open-source contributions. This demonstrates how instruction-based prompting becomes powerful and adaptable when multiple components are layered together.
4. In-Context Learning - Providing examples
Large Language Models (LLMs) do not “learn” in the traditional sense during inference. Instead, they adapt to patterns given in the prompt itself. This ability to condition their behavior on a few examples provided at runtime is called In-Context Learning (ICL).
4.1 The Idea Behind ICL
By showing the model examples of the task and the desired outputs, we “teach” it on the fly. The model does not change its weights; rather, it uses the examples as a temporary pattern guide to align its responses with the given format.
This makes ICL especially powerful when:
-
We don’t want to fine-tune the model.
-
Training data for fine-tuning is small or unavailable.
-
We want flexibility to change tasks quickly.
4.2 Types of In-Context Learning
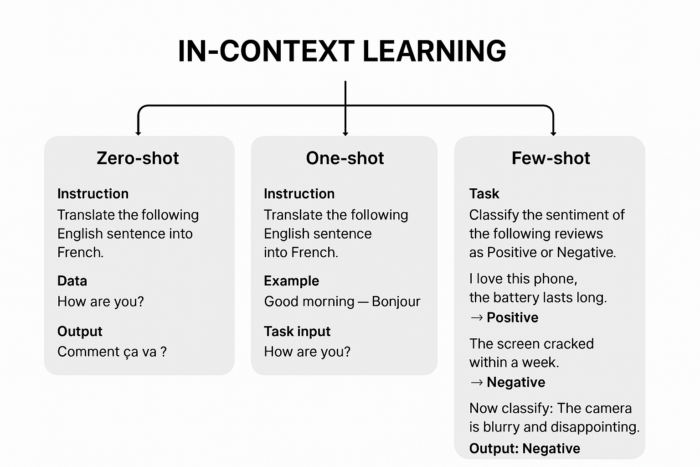
1. Zero-shot prompting
-
No examples are provided, only instructions.
-
Works best when the task is common or well-aligned with the model’s pretraining.
-
Example:
Instruction: Translate the following English sentence into French. Data: "How are you?" Output: "Comment ça va ?"
2. One-shot prompting
-
A single example is given to demonstrate the expected behavior.
-
Useful when the task requires clarity in format or style.
-
Example:
User: Translate the following English sentence into French. Example Input: "Good morning" → Example Output: "Bonjour" Task Input: "How are you?" Output: "Comment ça va ?"
3. Few-shot prompting
-
Multiple examples are given before the actual task.
-
Works well when tasks are ambiguous or domain-specific.
-
Example:
Task: Classify the sentiment of the following reviews as Positive or Negative. Review: "I love this phone, the battery lasts long." → Positive Review: "The screen cracked within a week." → Negative Review: "Excellent sound quality and fast processor." → Positive Now classify: "The camera is blurry and disappointing." Output: Negative
The following diagram illustrates the examples of in-context learning.
4.3 Importance of Role Differentiation
When writing few-shot prompts, clearly distinguishing roles (e.g., User: and Assistant: or Q: and A:) helps the model mimic the structure consistently. Without role markers, the model may drift into producing unstructured responses.
For example:
User: What is 2 + 2? Assistant: 4 User: What is 5 + 3? Assistant: 8 User: What is 7 + 6? Assistant:This encourages the model to continue in the same call-and-response pattern.
4.4 Benefits of In-Context Learning
-
Flexibility – You can “train” the model on a new task instantly without modifying its parameters.
-
Rapid prototyping – Great for testing new use cases before investing in fine-tuning.
-
Control – Helps enforce formatting (e.g., JSON, tables, bullet points).
4.5 Limitations of In-Context Learning
-
Context length constraints – Too many examples may exceed the model’s context window.
-
Random sampling – Even with examples, the model may ignore instructions if randomness (temperature, top_p) is high.
-
Cost & latency – Longer prompts = higher compute and inference cost.
-
Inconsistency – The same examples may yield slightly different outputs.
4.6 Advanced Variants of ICL
-
Instruction + Demonstration Hybrid: Combine explicit task instructions with few-shot examples for stronger guidance.
-
Chain-of-Thought with ICL: Provide examples that include reasoning steps, so the model learns to “think out loud” before answering.
-
Style Transfer with ICL: Use few-shot examples to enforce a particular writing style (e.g., Shakespearean, academic, casual).
5. Chain Prompting: Breaking up the Problem
When dealing with complex tasks, asking a large language model (LLM) to solve everything in a single prompt often leads to suboptimal results. The model may lose focus, misinterpret requirements, or generate incomplete answers. Chain prompting is a structured strategy where we break down a large problem into smaller subtasks, design prompts for each subtask, and then link them sequentially, passing outputs from one prompt as inputs to the next. This creates a pipeline of prompts that together achieve the final solution.
This approach mirrors how humans naturally solve complex problems—by breaking them into manageable steps rather than attempting everything at once.
5.1 Key Benefits of Prompt Chaining
-
Better Performance
-
By focusing each prompt on a single subtask, the LLM can generate more accurate and high-quality responses.
-
Reduces cognitive overload for the model.
-
-
Transparency
-
Each intermediate step in the chain is visible and explainable.
-
Makes it easier for developers and users to trace how the final output was constructed.
-
-
Controllability and Reliability
-
Developers can adjust or fine-tune only the prompts for the weaker subtasks instead of rewriting the entire large prompt.
-
More control over model behavior.
-
-
Debugging
- Since outputs are broken into stages, it’s easier to identify where an error occurs and fix it.
-
Incremental Improvement
- You can evaluate the performance of each subtask independently and selectively improve weak links in the chain.
-
Conversational Assistants
- Useful for designing chatbots where conversation naturally involves sequential reasoning (e.g., clarifying intent → retrieving information → generating response).
-
Personalization
- Chains can be designed to collect user preferences at one step and then apply those preferences consistently across subsequent prompts.
5.2 Common Use Cases
-
Response Validation
-
Prompt 1: Generate an answer.
-
Prompt 2: Ask the model (or another model) to evaluate correctness, consistency, or bias in the answer.
-
Example: LLM generates an explanation of a concept, then another LLM verifies if the explanation is factually correct.
-
-
Parallel Prompts
-
Sometimes, different subtasks can be run simultaneously.
-
Example: One prompt generates a list of features, another generates customer pain points, and later prompts merge them to design marketing copy.
-
-
Creative Writing / Storytelling
-
Prompt 1: Generate character descriptions.
-
Prompt 2: Use characters to generate a plot outline.
-
Prompt 3: Expand the outline into a full story.
-
-
Business Use Case – Marketing Flow
-
Step 1 (Prompt 1): Generate a catchy product name.
-
Step 2 (Prompt 2): Using the product name + product features, generate a short slogan.
-
Step 3 (Prompt 3): Using the product name, features, and slogan, generate a full sales pitch.
-
This modular approach ensures the final pitch is consistent, creative, and logically structured.
-
5.3 Prompt Chain Example
The following example illustrates the prompt chain that first creates a product name, then uses this name with product features to create a slogan, and finally uses features, product name, and slogan to create the sales pitch.
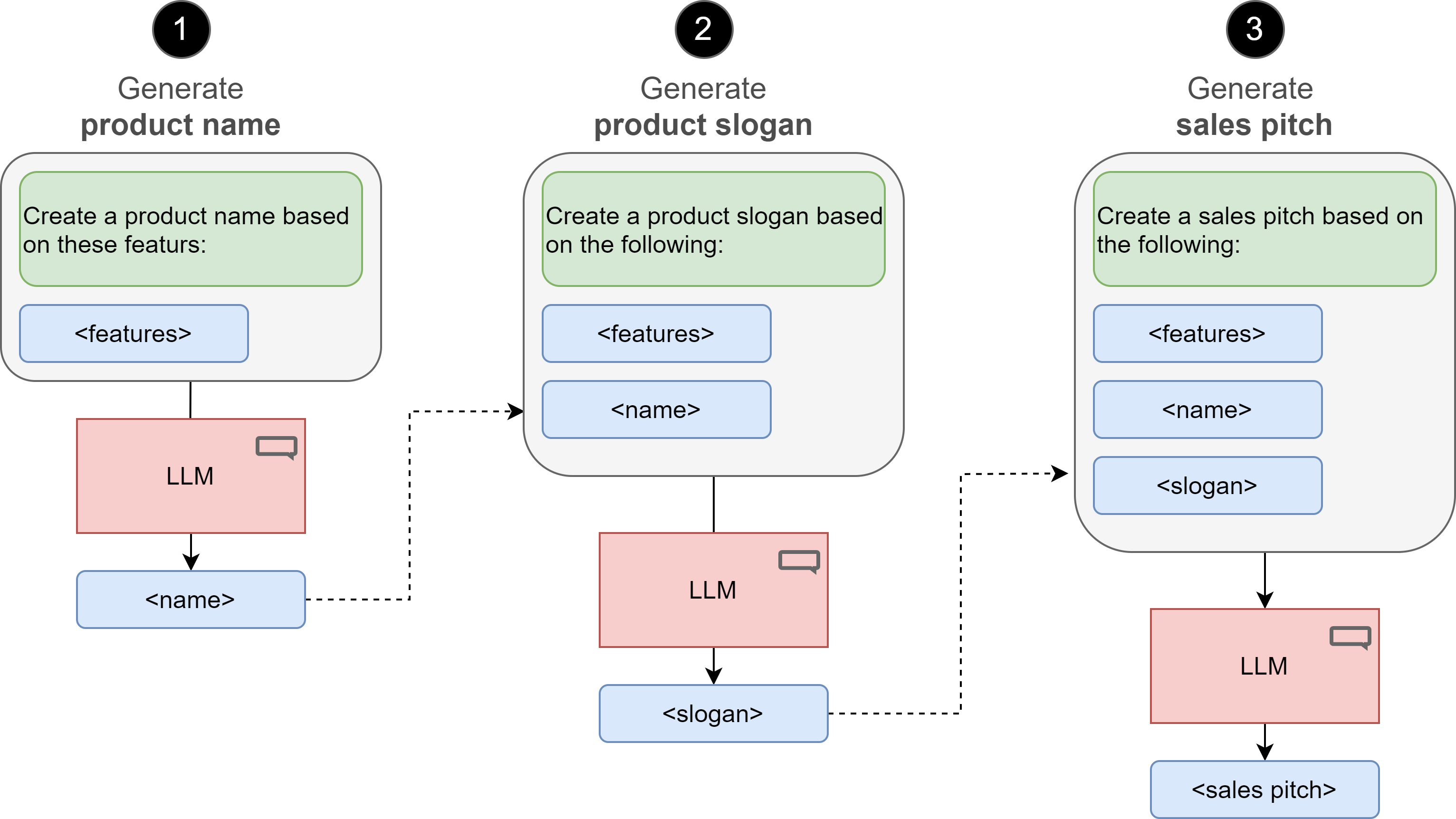
Step 1 – Product Naming
Instruction: “Suggest a creative name for a new smartwatch that focuses on health tracking and long battery life.”Output: “PulseMate”Step 2 – Slogan Generation
Instruction: """Using the product name ‘PulseMate’ and the features (health tracking, long battery life), create a short catchy slogan."""Output: “PulseMate – Your Health, Powered All Day.”Step 3 – Sales Pitch
instruction = """Using the product name "PulseMate" and its slogan"Your Health, Powered All Day," along with the features(health tracking, long battery life),write a compelling sales pitch for customers."""Output: “Meet PulseMate, the smartwatch designed to keep up with your lifestyle. Track your health seamlessly while enjoying a battery that lasts for days. PulseMate—Your Health, Powered All Day.”5.4 Variants of Prompt Chaining
-
Sequential Chaining – Output of one prompt feeds directly into the next (step-by-step). The above example in Figure 7 demonstrates sequential chaining.
-
Branching Chaining – One output is used to create multiple different paths of prompts.
-
Merging Chains – Combine results from different parallel chains into a unified final response.
-
Iterative Chaining – Loop a prompt multiple times for refinement (e.g., “revise this until it’s concise and clear”).
6. Reasoning with Generative Models
LLMs don’t “reason” like humans. They excel at pattern completion over very large text corpora. With careful prompting, scaffolding, and verification, we can simulate aspects of reasoning and markedly improve reliability.
6.1 System 1 vs. System 2 (Kahneman) — and LLMs
-
System 1 (fast, intuitive): In LLMs this looks like single-shot answers, low token budget, low/no deliberation. Good for well-trodden tasks (grammar fixes, casual Q&A).
-
System 2 (slow, deliberate): In LLMs this is multi-step prompting, intermediate reasoning, tool use (calculator/RAG), sampling multiple candidates, and verification. Good for math, logic, policy checks, multi-constraint generation, and anything high-stakes.
In practice: choose System 1 for speed/low risk; escalate to System 2 scaffolds when accuracy, traceability, or multi-constraint synthesis matters.
6.2 Techniques to Induce Deliberation
6.2.1 Chain-of-Thought (CoT): “Think before answering”
Elicit intermediate reasoning steps prior to the final answer.
Zero-shot CoT trigger (minimal):
You are solving a reasoning task.First, think step-by-step in brief bullet points.Then, give the final answer on a new line prefixed with "Answer:".Question: <problem>Few-shot CoT (when format matters): include 1–3 worked examples showing short, crisp reasoning and a clearly marked Answer line.
Tips
-
Keep thoughts succinct to reduce cost and drift.
-
For production UIs, you can ask the model to hide the rationale and output only the final answer + a confidence or citation list (see “Reasoning privacy” below).
When to use: arithmetic/logic puzzles, planning, constraint satisfaction, data transformation with edge cases.
The following figure demonstrates standard prompting vs C-o-T Prompting:
![Figure 9: Chain-of-thought example; reasoning process is highlighted - source [3]](/images/2025/03/chain-of-though-example-from-paper.png)
The following is an example of zero-shot chain-of-thought.
![Figure 10: Example of zero-shot chain-of-thought - source[1]](/images/2025/03/Diagram-zero-shot-chain-of-thought.drawio-1.png)
6.2.2 Self-Consistency: sample multiple rationales and vote
Rather than trusting the first reasoning path, sample k solutions and aggregate.
Template
Task: <problem>Instruction:Generate a short, step-by-step rationale and final answer.Vary your approach each time.[Run this prompt k times with temperature ~0.7–1.0]Aggregator:- Extract the final answer from each sample.- Choose the majority answer (tie-break: pick the one supported by the clearest rationale).- Return "Final:" <answer> and "Support count:" <m/n>.Practical defaults
-
k = 5–15 (trade accuracy vs. latency/cost)
-
temperature: 0.7–1.0
-
top_p: 0.9–1.0
When to use: problems with one correct output but many valid reasoning paths (math, logical deduction, label inference).
The following diagram illustrates the concept of self-consistency.
![Figure 11: Example of self-consistency in CoT[4]](/images/2025/03/self-consistency-paper.png)
6.2.3 Tree of Thoughts (ToT): explore and evaluate branches
Generalizes CoT into a search over alternative “thoughts” (states). You expand multiple partial solutions, score them, prune weak ones, and continue until a budget is reached.
Lightweight ToT pseudo-workflow
state0 = problem descriptionfrontier = [state0]for depth in 1..D: candidates = [] for s in frontier: thoughts = LLM("Propose 2-3 next-step thoughts for: " + s) for t in thoughts: v = LLM("Rate this partial approach 1-5 for promise. Be strict.\nThought: " + t) candidates.append((t, v)) frontier = top_k(candidates, by=v, k=K)best = argmax(frontier, by=v)answer = LLM("Given this best chain of thoughts, produce the final answer:\n" + best)Tuning knobs
-
D (max depth), K (beam width), value function (how you score thoughts), and token budget.
-
Use “look-ahead” prompts: “Simulate next two steps; if dead-end, backtrack.”
When to use: multi-step planning (itineraries, workflows), puzzle solving, coding strategies, complex document transformations.
The following diagram illustrates the various approaches to problem-solving with LLMs. Each rectangular box represents a thought.
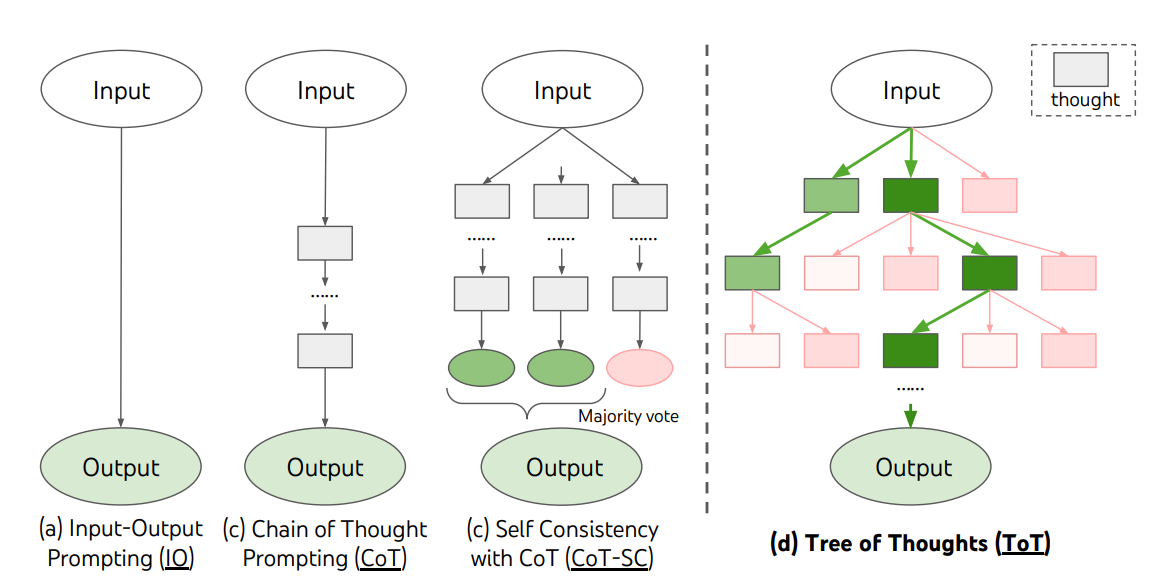
6.2.4 Related, practical reasoning scaffolds
-
ReAct (Reason + Act): Interleave “Thought → Action (tool call/RAG) → Observation” until done. Great for tasks that need tools, search, or databases.
-
Program-of-Thoughts (PoT): Ask the model to output code (e.g., Python) to compute the answer; execute it; return result. Excellent for math, data wrangling, and reproducibility.
-
Debate / Critic-Judge: Have model A propose an answer, model B critique it, and a judge (or the same model) select/merge. Pairs well with self-consistency.
-
Plan-then-Execute: Prompt 1 creates a plan/checklist; Prompt 2 executes step by step; Prompt 3 verifies outputs against the plan.
-
Retrieval-Augmented Reasoning: Prepend cited context (docs, policies) and require grounded (“quote-and-justify”) answers.
6.3 Putting it together: a robust System-2 pipeline
Use case: Policy compliance check for marketing copy.
-
Extract constraints (CoT):
“List policy rules relevant to social ads, each with an ID and short paraphrase.” -
Assess violations (ReAct/PoT):
For each rule, analyze the ad text; returnpass|failwith span references. -
Self-consistency vote:
Sample assessments 7× and majority-vote each rule outcome. -
Summarize & justify:
Compose a final verdict with a table of rules, decisions, and cited spans. -
Verifier pass:
A separate prompt re-checks logical consistency and that every failure has evidence. -
Guarded output:
Enforce schema (JSON) and redact PII (Redacting or identifying personally identifiable information).
This gives you accuracy (deliberation), transparency (artifacts per step), and control (schema + verifier).
6.4 Operational Guidance
6.4.1 Prompt templates
CoT (short)
Solve the problem. First give 3-5 brief reasoning bullets. Then output the final result as: "Answer: <value>".Question: <...>Self-consistency runner (controller code)
answers = []for i in range(k): ans = call_llm(prompt, temperature=0.8, top_p=0.95) answers.append(extract_final(ans))final = majority_vote(answers)ReAct skeleton
Thought: I need the latest spec section.Action: search("<query>")Observation: <top snippet>Thought: Summarize the relevant passage and apply the rule....Final Answer: <concise verdict + citation>ToT node expansion
Propose 3 distinct next-step ideas to advance the solution.For each: give a one-sentence rationale and a 1-5 promise score.Return JSON: [{"idea":..., "rationale":..., "score":...}]6.5 Evaluation & QA
Once we design and deploy prompts, evaluation and quality assurance (QA) become critical. Unlike traditional software, where behavior is deterministic, LLM outputs are probabilistic and context-dependent. This means even well-designed prompts may fail in certain conditions. A structured evaluation strategy helps measure reliability, accuracy, and efficiency of your prompt-engineering pipeline.
Evaluation can be broadly divided into four dimensions: task accuracy, process metrics, ablations, and cost/latency.
1. Task Accuracy – Measuring End Results
The first dimension is whether the model actually solves the task correctly. Depending on the nature of the application, different metrics apply:
-
Exact Match (EM): Used for tasks where there is a single correct answer (e.g., classification, math problems, SQL query generation). Checks if the model output matches the ground truth exactly.
-
F1 Score: Measures overlap between predicted tokens and ground-truth tokens, balancing precision and recall. Common for QA and NER tasks.
-
pass@k: Especially used in code generation, where we test if any of the top-k sampled outputs are correct (e.g., pass@1, pass@10).
-
BLEU / ROUGE: Standard metrics for summarization, translation, and text generation tasks, where multiple valid outputs may exist.
-
Domain-Specific Metrics:
-
Medical: accuracy of ICD codes, dosage consistency.
-
Finance: correctness of risk scores, compliance alignment.
-
Legal: citation accuracy, contract clause matching.
-
Task accuracy answers: Did the model get it right?
2. Process Metrics – Evaluating the Reasoning Path
Sometimes the final answer looks right, but the process is flawed. Evaluating intermediate reasoning steps ensures robustness:
-
Step Validity Rate: In CoT or ToT prompting, check if each intermediate reasoning step is logically valid.
-
Verifier Agreement: Use an external verifier model (or human annotators) to check whether the reasoning aligns with domain knowledge.
-
Citation Coverage: For knowledge-grounded tasks, measure how many claims in the output are backed by explicit references (retrieved documents, database entries).
-
Hallucination Rate: % of outputs containing unsupported or fabricated facts.
Process metrics answer: Did the model follow a sound reasoning path, not just guess the final answer?
3. Ablation Studies – Quantifying the Effect of Prompting Techniques
Prompt engineering often involves experimenting with different prompting strategies. Ablation studies allow us to isolate what works best by systematically varying one factor at a time.
-
Single-Shot vs. CoT (Chain-of-Thought): Compare baseline prompts against CoT prompting to measure reasoning improvements.
-
CoT vs. CoT+SC (Self-Consistency): Test whether sampling multiple reasoning paths and aggregating improves accuracy.
-
ToT (Tree-of-Thought): Compare CoT vs. ToT to see if deliberate multi-path exploration boosts complex problem-solving.
-
Role of Examples: Zero-shot vs. one-shot vs. few-shot performance.
This helps quantify the lift (improvement in accuracy or reasoning reliability) due to advanced prompting.
Ablations answer: Which prompting strategy gives the best performance trade-off?
4. Cost & Latency – Operational Constraints
In production, even the most accurate system fails if it’s too slow or expensive. Evaluation must include efficiency metrics:
-
Tokens per Step: Track how many tokens are consumed per prompt and per reasoning step. Helps understand scaling behavior.
-
Cache Intermediate Artifacts: Save partial reasoning outputs (e.g., retrieved documents, intermediate JSONs) to avoid recomputation.
-
Latency per Request: Time taken for one query end-to-end (prompt → LLM → post-processing).
-
Cost per Query: Estimate $$ spent per API call or GPU inference, especially with multi-step chains (CoT, ToT).
-
Trade-off Curves: Accuracy vs. cost/latency curves, to decide the optimal configuration for production.
Cost/latency metrics answer: Is the solution practical at scale?
A robust evaluation framework should combine accuracy, process validity, ablations, and cost tracking. Only then can we say our prompt engineering strategy is not just clever in theory, but reliable, efficient, and production-ready.
6.6 Safety & reliability
Ensuring safety and reliability in prompt engineering is one of the most critical aspects when deploying LLM-powered applications in production. Without guardrails, models may generate unsafe, incoherent, or unpredictable responses that can result in privacy leaks, reputational damage, or compliance violations. This section outlines key strategies for strengthening the robustness of generative AI systems.
🔒 Reasoning Privacy
- Hidden rationale vs. exposed reasoning:
-
When using techniques like Chain-of-Thought (CoT) prompting, models produce intermediate reasoning steps. While useful for debugging or internal evaluation, exposing these steps to end users may inadvertently leak sensitive information, such as internal rules, confidential business logic, or hints about training data.
-
Best practice: Allow the model to perform its reasoning “behind the scenes,” but only expose the concise, final answer in the user-facing product. This keeps user interactions clean, prevents information leakage, and reduces the risk of misuse.
-
🛡️ Guardrails
Guardrails act as safety filters and structural enforcements that make outputs predictable, secure, and policy-compliant. They operate at two levels:
-
Structural Guardrails
- Constrain model outputs using:
-
JSON schemas → ensure the output always matches a machine-parseable format.
-
Regex patterns → validate strict textual outputs (e.g., email, date, currency).
-
Formal grammars → force models to follow defined syntactic structures.
-
- Constrain model outputs using:
-
Content Guardrails
- Citations for claims: Require models to attach evidence (links, references) for factual statements to minimize hallucinations.
- Policy / PII filters: Run input and output through filters that detect:
- Personally Identifiable Information (names, addresses, SSNs, etc.)
- Toxicity (hate speech, profanity, culturally sensitive stereotypes)
- Safety issues (violence, self-harm, disallowed content)
Frameworks such as Guardrails AI, LMQL, or Guidance provide programmatic ways to enforce these constraints.
⚙️ Determinism Knobs
LLMs are inherently probabilistic, meaning the same prompt may yield different outputs on different runs. For enterprise-grade reliability, determinism can be controlled via:
-
Lowering Temperature
-
Reduces randomness in token sampling.
-
At temperature = 0, the model becomes nearly deterministic, always picking the most probable token.
-
-
Self-Consistency with Majority Voting
-
Instead of accepting a single output, the model generates multiple reasoning paths (using Chain-of-Thought).
-
A majority vote across outputs ensures stability and reduces the impact of outlier generations.
-
Example: In a math problem, the model might produce 5 possible solutions; by selecting the most common final answer, reliability improves.
-
Safety and reliability in prompt engineering require balancing privacy (hidden reasoning), structural/content guardrails (schemas, filters, citations), and deterministic controls (temperature, self-consistency). These practices make LLM-powered systems not only smarter but also trustworthy, compliant, and production-ready.
6.7 When not to use heavy reasoning
While techniques like Chain-of-Thought (CoT), Tree-of-Thought (ToT), or self-consistency sampling can significantly improve reasoning quality in Large Language Models (LLMs), they are not always the right choice. Heavy reasoning often comes at the cost of latency, cost, and computational overhead. In certain contexts, it is better to avoid them altogether and rely on simpler, faster prompting strategies.
Here are situations where heavy reasoning is unnecessary or even counterproductive:
🔹 1. Simple, Well-Known Tasks Where Single-Shot Responses Are Accurate
Not every task requires multiple reasoning steps. If the task has a clear, deterministic answer and can be handled with a single-shot prompt, adding chain-of-thought or multi-step reasoning only adds complexity without benefit.
Examples:
-
Asking factual questions with unambiguous answers:
“What is the capital of France?” → “Paris” -
Formatting tasks:
Convert1234to Roman numerals →MCCXXXIV -
Standardized classification:
Sentiment analysis of short product reviews → “Positive/Negative”
👉 In such cases, heavy reasoning only increases inference time and may even introduce noise (e.g., overthinking a trivial fact).
🔹 2. Ultra-Tight Latency Budgets
Reasoning methods like CoT or ToT require more tokens because they expand the answer into intermediate steps before concluding. This makes them slower and more expensive.
If the application has strict response time requirements, such as:
-
Customer support chatbots expected to respond in <1 second.
-
Voice assistants where delays break the conversational flow.
-
High-frequency trading AI where every millisecond counts.
👉 In these scenarios, it’s better to stick with direct, single-shot answers or pre-validated responses instead of reasoning chains. Latency constraints make heavy reasoning impractical.
🔹 3. Very Small Models Without Enough Capacity or Context Window
Advanced reasoning prompts assume the model has sufficient capacity (parameters) and context length to simulate multi-step reasoning. Very small models (e.g., <1B parameters, or edge-deployed models with small context windows) often fail to benefit from reasoning prompts because they:
-
Forget earlier reasoning steps due to short context limits.
-
Generate incoherent or circular reasoning when asked to “think step by step”.
-
Struggle to hold multiple candidate reasoning paths in memory (needed for self-consistency or ToT).
Example:
- Running CoT on a mobile LLM with 1B parameters may just produce verbose, repetitive text instead of genuine reasoning.
👉 For such models, it is better to use direct, concise prompting and offload complex reasoning to a larger backend model if required.
⚖️ Trade-Offs: Accuracy vs. Efficiency
| Scenario | Reasoning Style | Why |
|---|---|---|
| Simple, factual Q&A | Single-shot | Faster, cheaper, reliable |
| Creative writing | CoT / ToT | Requires exploration & coherence |
| Real-time chatbot | Single-shot / lightweight CoT | Minimize latency |
| Legal/medical analysis | CoT + self-consistency | Accuracy more important than speed |
| Edge device app | Single-shot | Small models can’t handle CoT well |
Heavy reasoning should be used selectively. It shines in complex, ambiguous, or multi-step reasoning problems, but for simple, latency-sensitive, or resource-constrained scenarios, sticking with direct prompting leads to better user experience and system efficiency.
Quick chooser: which technique when?
| Situation | Recommended scaffold |
|---|---|
| Arithmetic/logic puzzle | CoT → Self-consistency (k=5–15) |
| Multi-step planning / puzzle search | ToT (small D, K), optional ReAct for tools |
| Needs external data/tools | ReAct (with retrieval/calculator/code) |
| Deterministic data transformation | PoT (code execution) + schema constraints |
| High-stakes, audited outputs | CoT/ToT + Verifier + Guardrails + Logged artifacts |
7. Output Verification
In real-world deployments, verifying and controlling the output of generative AI models is crucial to ensure safety, robustness, and reliability. LLMs, while powerful, are prone to errors, hallucinations, ethical risks, or unstructured responses that can cause failures in production systems.
Without proper verification, issues such as malformed data, offensive content, or incorrect facts can undermine user trust and lead to business or compliance risks.
7.1 Why Output Verification Matters
-
Structured Output
-
Many applications require the output in machine-readable formats (e.g., JSON, XML, CSV).
-
An unstructured answer can break downstream systems expecting strict schemas.
-
-
Valid Output Choices
-
Even if the model is instructed to choose among fixed options (e.g., "positive" or "negative"), it may generate something outside the list (e.g., "neutral" or "very positive").
-
Output validation ensures strict adherence to predefined categories.
-
-
Ethical Compliance
-
Outputs must be free of profanity, bias, harmful stereotypes, or PII (Personally Identifiable Information).
-
Regulatory compliance (GDPR, HIPAA, etc.) requires strict filtering of sensitive or discriminatory outputs.
-
-
Accuracy and Reliability
-
LLMs can hallucinate — produce factually wrong but confident-sounding information.
-
Verification steps such as grounding with external knowledge bases or post-checking factual claims can prevent misinformation.
-
7.2 Methods to Control Output
Apart from tweaking generation parameters like temperature (randomness) and top_p (nucleus sampling), there are three primary strategies for enforcing correct outputs:
7.2.1 Providing Examples (Few-Shot Structured Prompts)
-
How it works:
-
Supply the model with examples of desired output in the correct format (e.g., JSON, Markdown tables).
-
The model uses these as patterns to mimic.
-
-
Example Prompt:
{ "name": "Alice", "sentiment": "positive"}Now classify the following:
Input: "The movie was fantastic!"
Output:
Limitations:
-
Models may still deviate, especially under ambiguous inputs.
-
Reliability varies across models — some are better at following formatting instructions than others.
7.2.2 Grammar-Based Constrained Sampling
Instead of relying only on examples, grammars and constraints can be enforced at the token generation level. This guarantees that outputs match the expected structure.
Techniques & Tools:
🔹 Guidance
-
A framework for programmatically controlling LLM outputs.Uses regex, context-free grammars (CFGs), and structured templates.Supports conditionals, loops, and tool calls inside prompt templates.
-
Advantage: Reduced cost and latency compared to brute-force fine-tuning.
🔹 Guardrails
-
Python framework to build safe, reliable AI pipelines.
-
Key features:
- Input/Output Guards to catch risks (bias, toxicity, PII leaks).Schema enforcement (ensures outputs comply with JSON, XML, etc.).Ecosystem of reusable validators via Guardrails Hub.
Example: Ensuring LLM output is a safe, validated JSON object representing a chatbot reply.
🔹 LMQL (Language Model Query Language)
-
Specialized programming language for LLM prompting.
-
Provides types, templates, and constraints for robust prompting.
-
Runtime ensures the model adheres to the defined schema during decoding.
Low-level Constrained Decoding Example (llama-cpp-python):
response = llm( "Classify the sentiment.", response_format = {"type": "json_object"})Forces the model to output a valid JSON object instead of free text.
7.2.3 Fine-Tuning for Desired Outputs
-
How it works:
-
Retrain or fine-tune the base model on domain-specific datasets that already contain the desired output style.
-
Example: A customer support LLM fine-tuned only on safe, structured responses in JSON.
-
-
Benefits:
-
Reduces variance and unpredictability.
-
Makes structured outputs more native to the model (less prompt engineering overhead).
-
-
Limitations:
-
Requires labeled data in the target output format.
-
Costly and time-consuming compared to prompting or grammar constraints.
-
7.3 Output Verification Pipeline (Best Practice)
A robust production system often combines multiple techniques:
-
Prompt-level control → Provide few-shot examples of structured output.
-
Grammar/Constraint enforcement → Enforce schema compliance (Guidance, Guardrails, LMQL, or constrained decoding APIs).
-
Post-generation validation → Apply validators for ethics, factuality, and compliance.
-
Fallback mechanism → If verification fails, rerun the model with tighter constraints or route to a human-in-the-loop system.
Output verification transforms LLMs from unpredictable text generators into reliable components of enterprise systems. By combining structured examples, constrained grammar, and fine-tuning, developers can build trustworthy AI applications that are safe, accurate, and production-ready.
References
-
Book: Oreilly – Hands-On Large Language Models – Language Understanding and Generation by Jay Alammar & Maarten Grootendorst
-
Paper: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models by Jason Wei et. al., Google Research, Brain Team
-
Paper: Self-Consistency improves Chain-of-Thought Reasoning in Language Models by Wang et. al., Google Research, Brain Team
-
Tree of Thoughts: Deliberate Problem Solving with Large Language Models by Shunyu yao et al. NIPS - 2023
-
Report on a general problem solving program by A. Newell et al. in IFIP congress - 1959
Related Articles
Natural Language Processing Nlp
- Building Production-Ready AI Agents with LangGraph: A Developer's Guide to Deterministic Workflows
- Hands-on Tutorial on Making an Audio Bot using LLM, and RAG
- How Google's SynthID Actually Works: A Visual Breakdown
Follow for more technical deep dives on AI/ML systems, production engineering, and building real-world applications: