1. Introduction
A common task in natural language processing (NLP) is text classification. Use cases of text classification include sentiment analysis, intent detection, entity extraction, and language detection. This article will delve into how to use LLMs for text classification. We will see representation models and generative models. Under the representation model, we will see how to use task-specific models and embedding models to classify the text. Under the generative models, we will see open source and closed source models. While both generative and representation models can be applied to classification, they take different approaches.
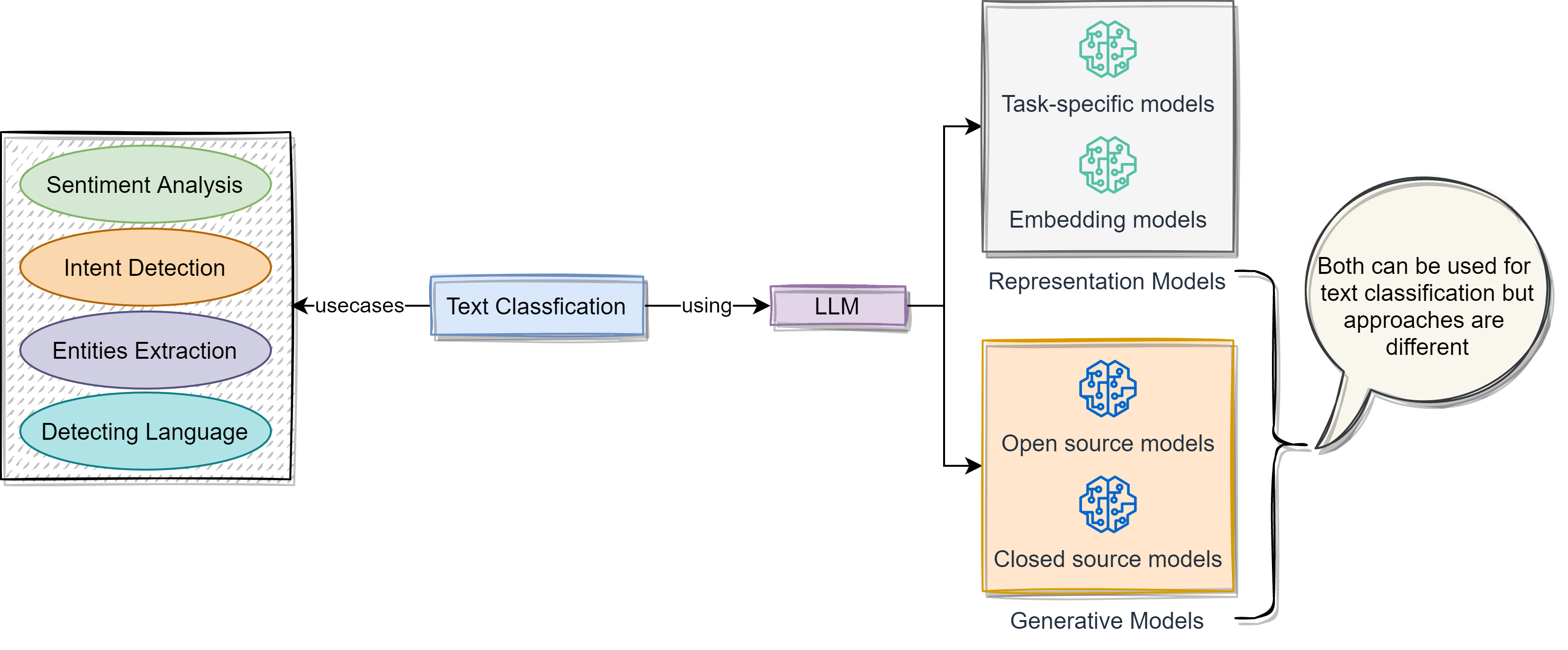
2. Text Classification with Representation Models
Task-specific models and embedding models are two types of representation models that can be used for text classification. To obtain task-specific models, representation models, like bidirectional encoder representations from transformers (BERT), are trained for a particular task, like sentiment analysis. On the other hand, general-purpose models such as embedding models can be applied to a range of tasks outside classification, such as semantic search.
As it can be seen in the below diagram, when used in the text classification use case, representation models are kept frozen (untrainable). As the task-specific models are specially trained for the given task, when the text is given as input, it can classify the given text as per the task at hand. But when we are using the embedding model, we need to generate embeddings for the texts in the training set. Then train a classifier on the train dataset that has embeddings and corresponding labels. Once the classifier is trained, it can be used for classification.
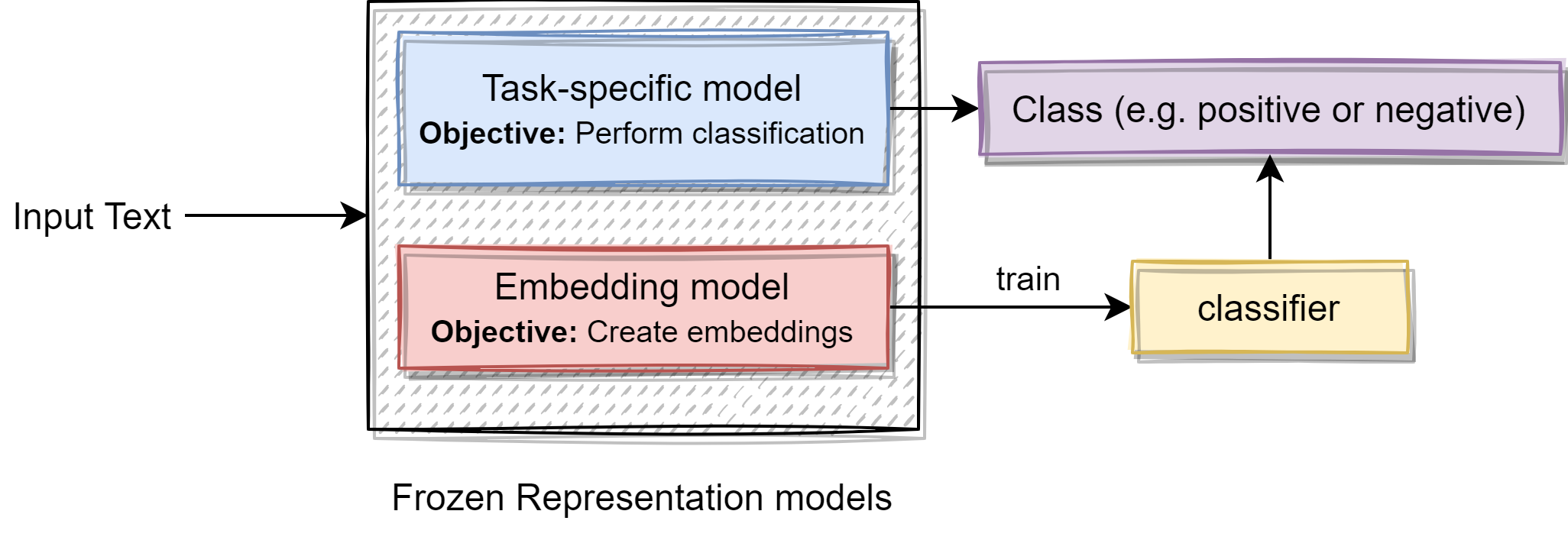
3. Model Selection
The factors we should look into for selecting the model for text classification:
-
How does it fit the use case?
-
What is its language capability?
-
What is the underlying architecture?
-
What is the size of the model?
-
How is the performance? etc.
Underlying Architecture
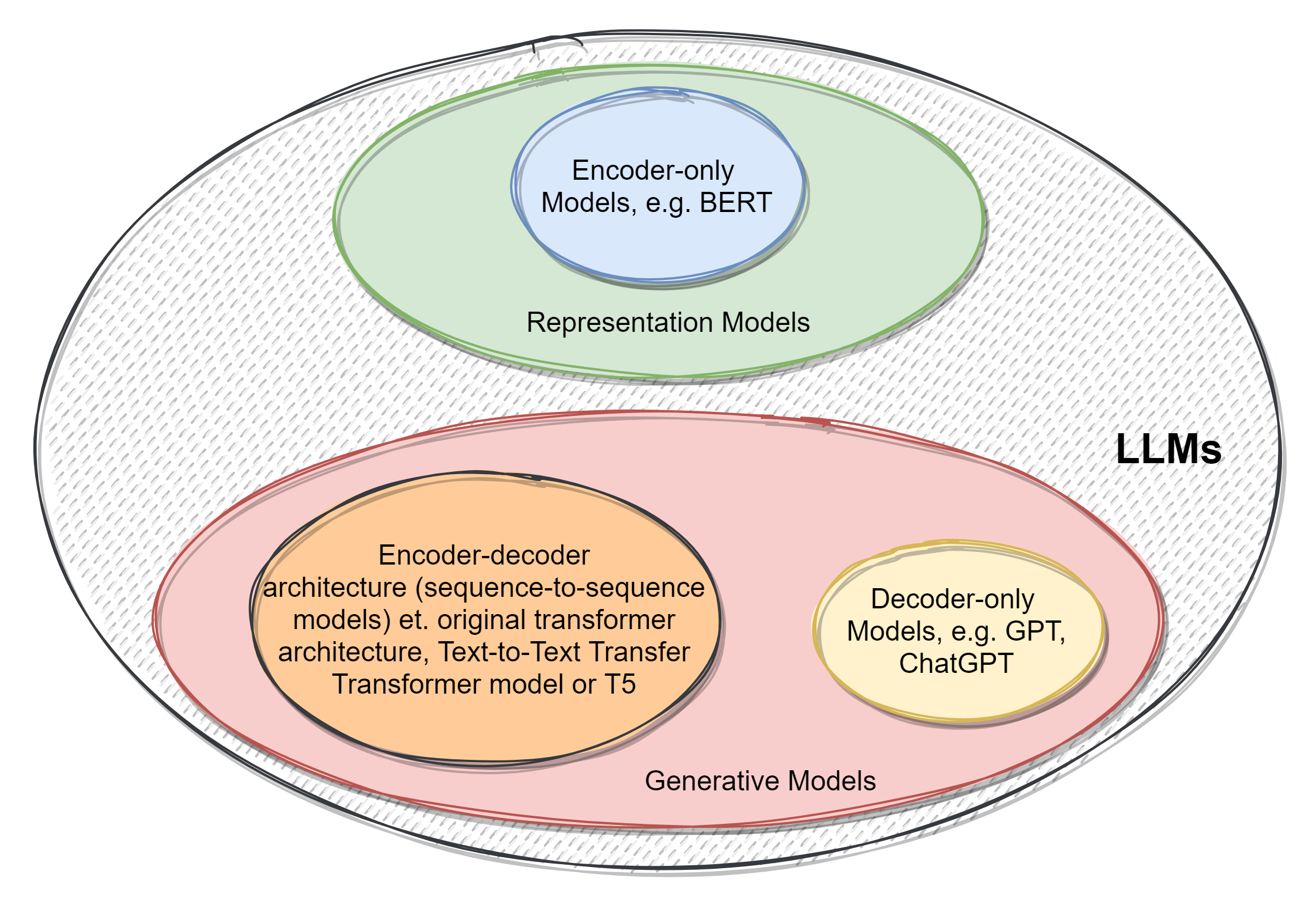
BERT is an encoder-only architecture and is a popular choice for creating task-specific models and embedding models, and falls into the category of representation models. Generative Pre-trained Transformer (GPT) is a decoder-only architecture that falls into the generative models category. Encoder-only models are normally small in size. Variations of BERT are RoBERTa, DistilBERT, DeBERTa, etc. For task-specific use cases such as sentiment analysis, Twitter-RoBERTa-base can be a good starting point. For embedding models sentence-transformers/all-mpnet-base-v2 can be a good starting point as this is a small but performant model.
4. Text Classification using Task-specific Models
This is pretty straight forward. Text is passed to the tokenizer that splits the text into tokens. These tokens are consumed by the task-specific model for predicting the class of the text.

This is fine if we could find the task-specific models for our use case. Otherwise, if we have to fine-tune the model ourselves, we would need to check if we have sufficient budget(time, cost) for it. Another option is to resort to using the general-purpose embedding models.
5. Text Classification using Embedding Models
We can generate features using an embedding model rather than directly using the task-specific representation model for classification. These features can be used for training a classifier such as logistic regression.

5.1 What if we do not have the labeled data?
We have the definition of the labels, but we do not have the labeled data, we can utilize what is called "zero-shot classification". Zero-shot model predicts the labels of input text even if it was not trained on them. Following diagram depicts the concept.
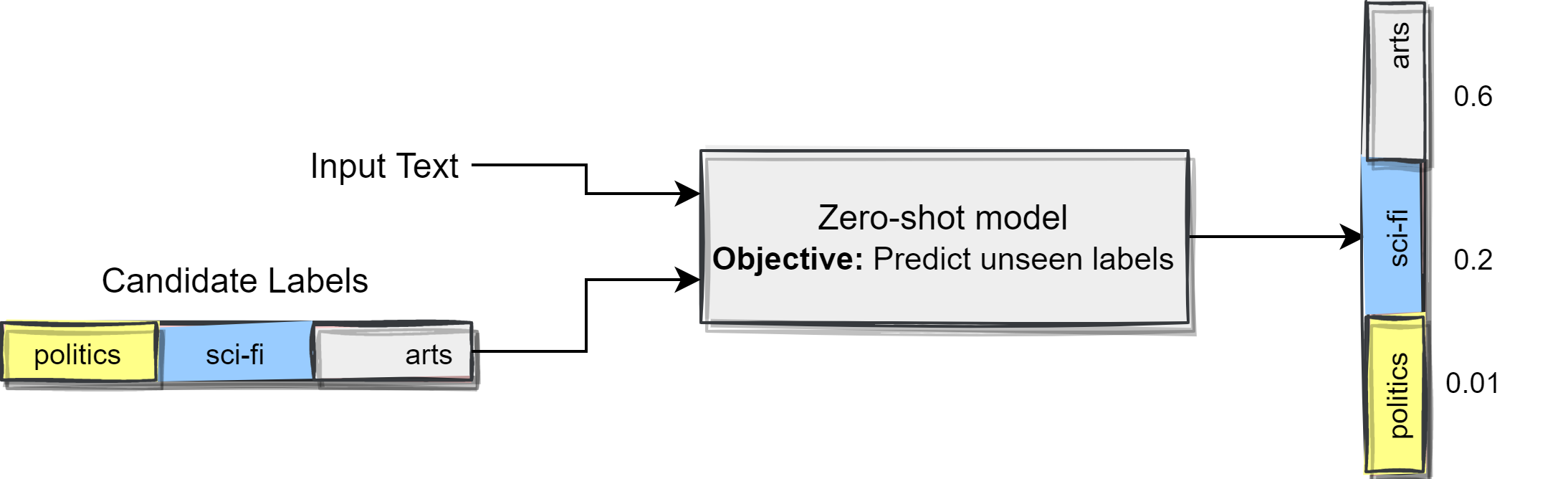
We can use zero-shot classification using embeddings. We can describe our labels based on what they should represent. The following diagram describes the concept.
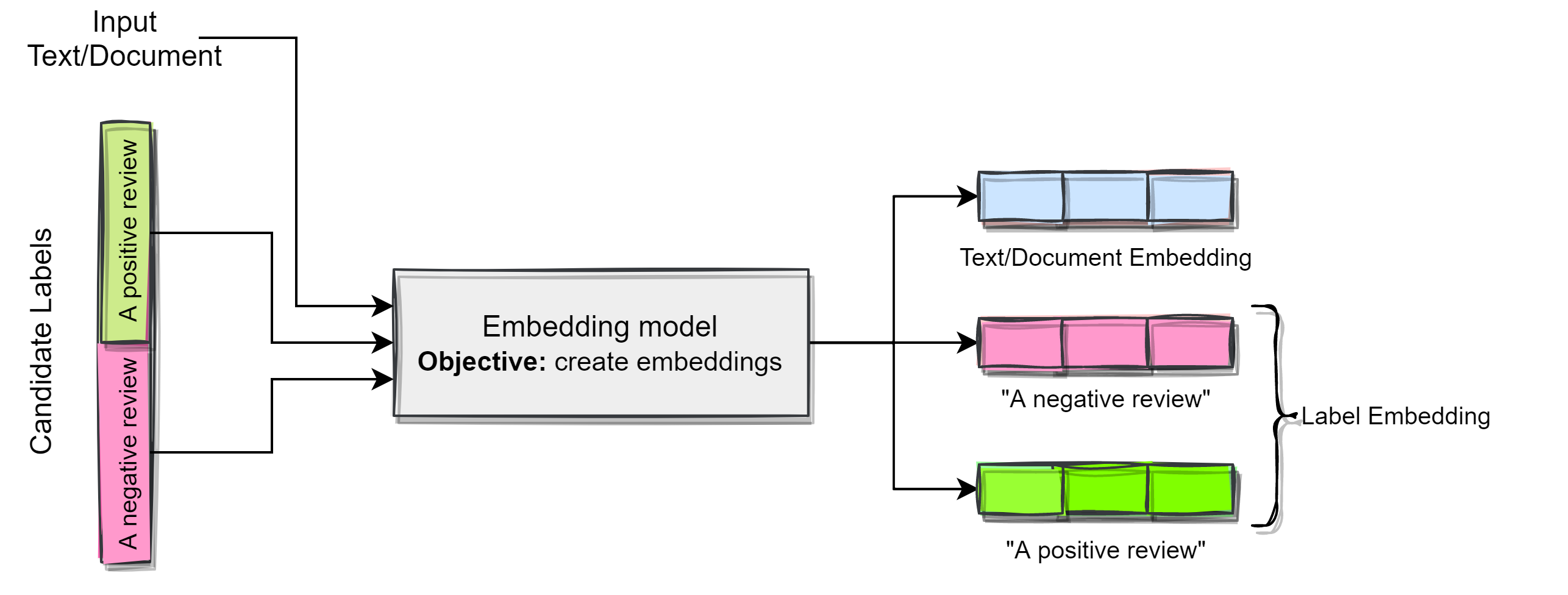
To assign the labels to the input text/document, we can calculate the cosine similarity with the label embeddings to check which label it is close to.
6. Text Classification with Generative Models
Generative models are trained for a wide variety of tasks, so it will not work with the text classification out of the box. To make the generative model understand our context, we need to use the concept of prompt engineering. The prompt needs to be cleverly written so that the model understands what it is expected to do, what the candidate labels, etc.

6.1 Using Text-to-Text Transfer Model (T5)
The following diagram summarizes the different categories of the models:
The following diagram depicts the training steps:

We need to prefix each document with the prompt "Is the following sentence positive or negative?"
6.2 ChatGPT for Classification
The following diagram describes the training procedure of ChatGPT:
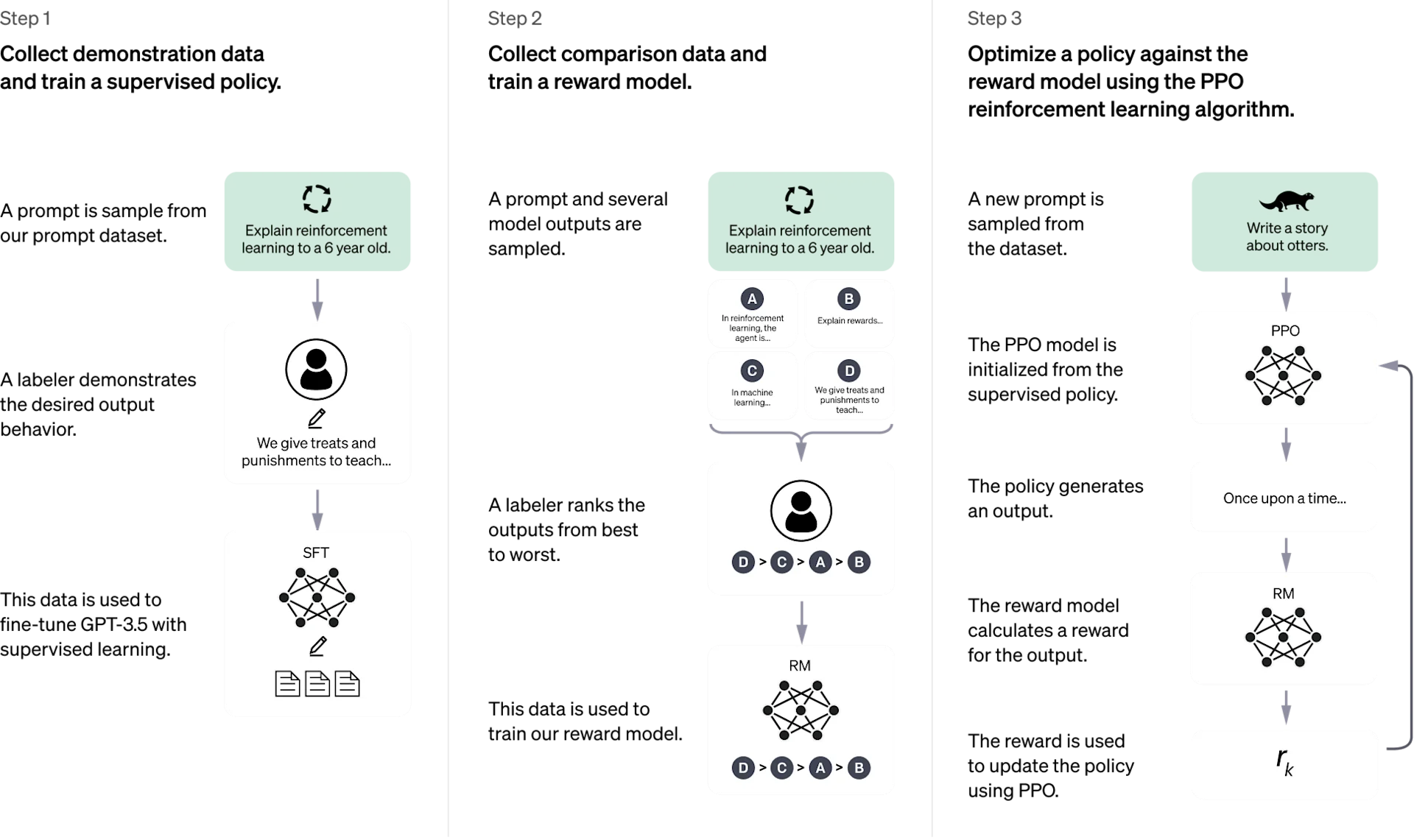
The model is trained using human preference data to generate text that resembles human preference.
For text classification, following is the sample prompt:
prompt = """Predict whether the following document is a positive or negative movie review:
[DOCUMENT]
If if is positive return 1 and if it is negative return 0. Do not give any other answers. """
References
-
Oreilly - Hands-On Large Language Models - Language Understanding and Generation by Jay Alammar & Maarten Grootendorst
-
Hugging Face - https://huggingface.co/
Related Articles
Natural Language Processing Nlp
- Hands-on Tutorial on Making an Audio Bot using LLM, and RAG
- My notes on AI-Generated Content (AIGC)
- On Emergent Abilities of Large Language Models
- Question Answer Chatbot using RAG, Llama and Qdrant
Follow for more technical deep dives on AI/ML systems, production engineering, and building real-world applications:


