Introduction
Let us look back to the early days of artificial intelligence when machine learning methods like support vector machines and decision trees were widely accepted and applied to practically every use case. Everything was explainable since it was possible to alter the model’s parameters and gain insight into how those changes would impact the model’s functionality and performance. The introduction of neural networks resulted in a significant increase in both the number of parameters and training time. Thus, the rate of developing intuition slowed down with time. Neural networks did not perform well at first. What, then, caused the neural networks to begin outperforming all other options?
The main drivers were the availability of large amounts of data and the development of computer power (GPUs). Another innovation in recent years has been transformer architecture. When ChatGPT was introduced in November 2022, AI exceeded many people’s expectations.
Development in the last decade
An overview of the developments during the past ten years is provided in the following figure. Given an image, for instance, it can recognize the item; given an audio input, it can convert it to text; it can translate text between languages; and given an image, it can produce an image description.
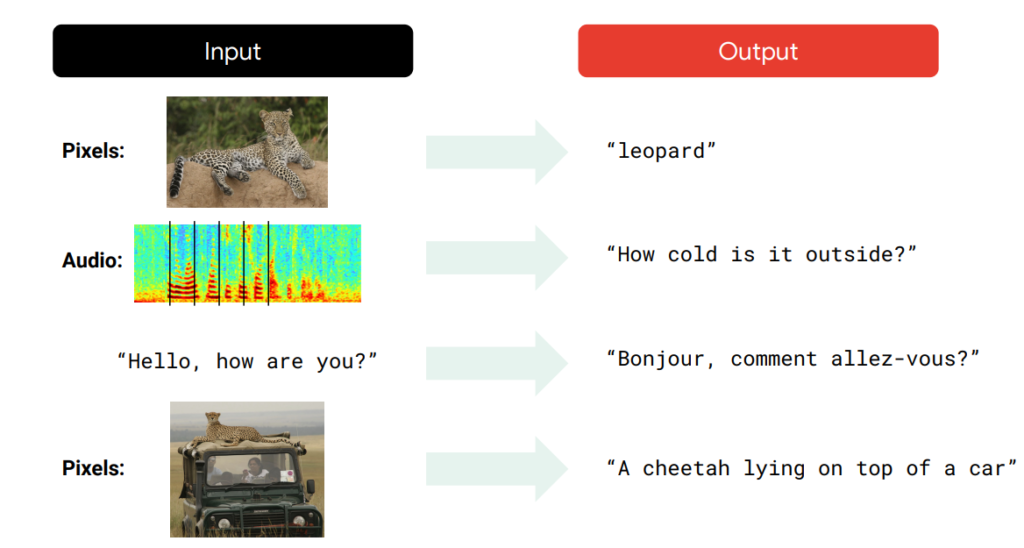
With the advent of Generative AI the output in the above image can become input, and data can be generated as output. For example, given the text, it can generate images, audio, video, etc.
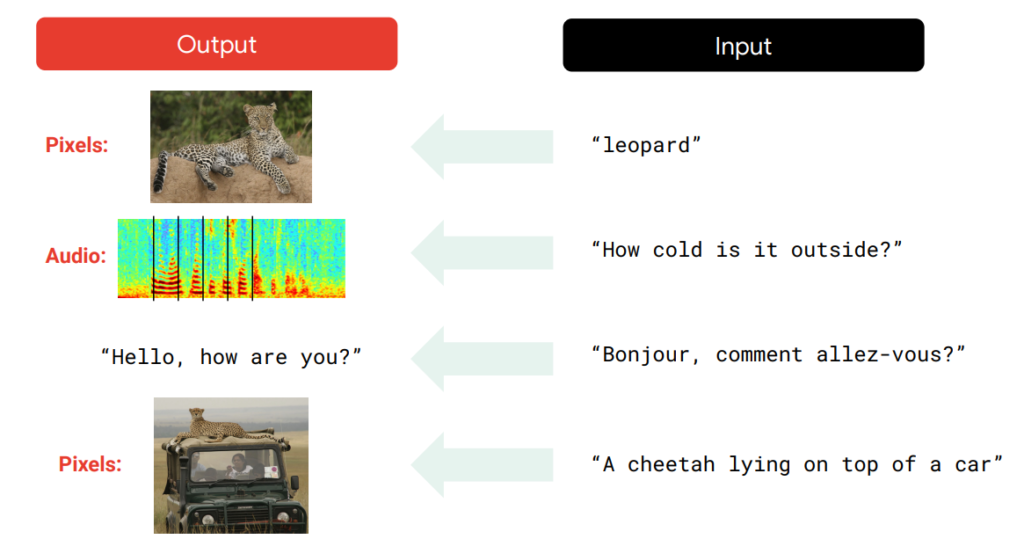
Pace of development
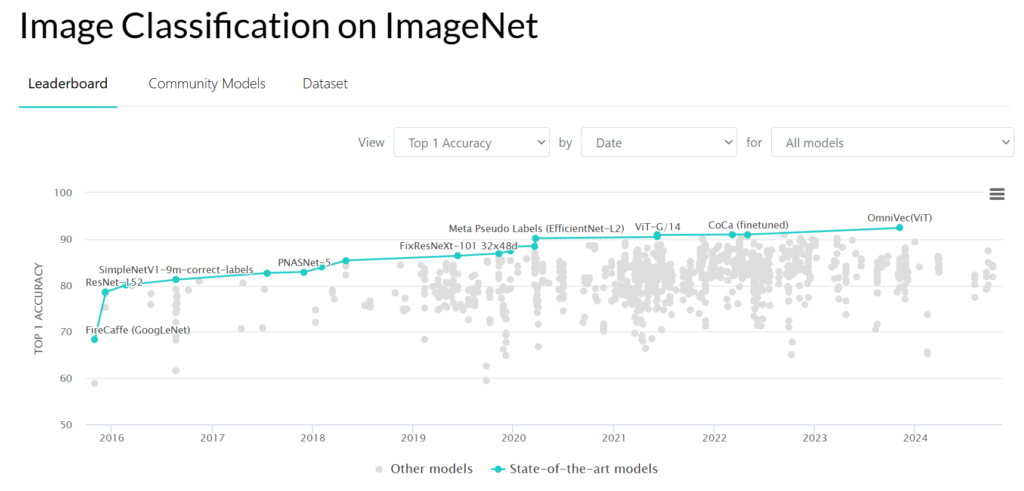
In the following figure, you can see the progress of image classification on the ImageNet dataset. Accuracy from around 50% in 2011, increased to 92% in 2024.
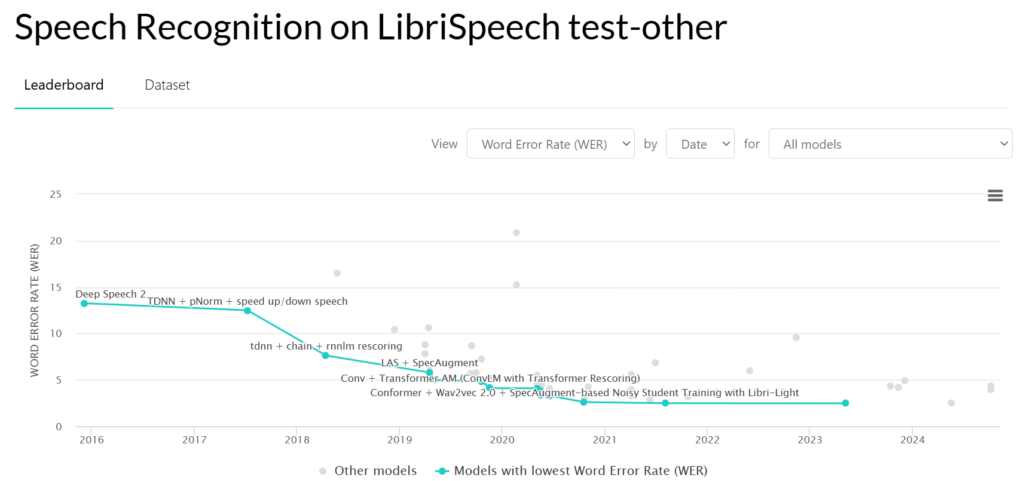
You can see the progress of Speech Recognition on LibriSpeech test-other in the following figure.
A Brief History of LLMs
Artificial Intelligence Generated Content (AIGC) is a larger category that includes Large Language Models (LLMs). It consists of AI models that produce written text, music, graphics, and other types of content. The following figure illustrates AIGC in image generation.
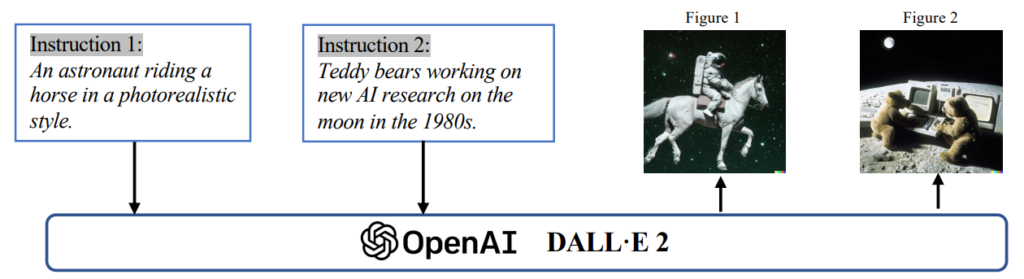
There are two types of GAI models: unimodal models and multimodal models. While multimodal models accept cross-modal instructions and generate outputs of diverse kinds, unimodal models get instructions from the same modality as the generated content modality. The following figure illustrates this in detail.

The two main parts of the generation process are typically extracting intent information from human instructions and producing content based on the intentions that have been collected. Training more complex generative models on bigger datasets, utilizing larger foundation model architectures, and having access to a wealth of computational resources are the main reasons why modern AIGC has advanced so much in comparison to earlier efforts. To find the best answer for a given instruction, ChatGPT uses reinforcement learning from human feedback (RLHF), which gradually increases the model’s accuracy and dependability. Generative diffusion models, such as stable diffusion, proposed by Stability.AI, generate high-resolution images by regulating the trade-off between exploration and exploitation, resulting in a harmonic blend of variation in the generated images and resemblance to the training data.
Generative models, such as Hidden Markov Models (HMMs) and Gaussian Mixture Models (GMMs), have been developed since the 1950s. However, deep generative models didn’t improve performance until the advent of deep learning in the 2010s. Traditional methods for generating sentences using N-gram language modeling are limited to short sequences, while recurrent neural networks (RNNs) and their variants can model longer dependencies and attend to around 200 tokens.
In computer vision, traditional algorithms used texture synthesis and mapping techniques based on hand-designed features. In 2014, Generative Adversarial Networks (GANs) were first proposed, providing significant improvements in generating diverse images. Later, Variational Autoencoders (VAEs) and diffusion models have been developed for more control over image generation and high-quality image creation.
The introduction of the Transformer architecture by Vaswani et al. in 2017 has become the foundation for generative models across various domains, including NLP (BERT, GPT) and computer vision (CV). This architecture combines visual components with transformer-based modeling, enabling multimodal tasks that integrate text and image information. The development of Vision Transformer (ViT) and Swin Transformer further advances this concept in CV, allowing for large-scale training on multimodal data.
Researchers are now exploring new techniques based on Transformer architecture, such as few-shot prompting in NLP, which uses only a few examples to help the model better understand task requirements. In computer vision, models combine modality-specific approaches with self-supervised learning objectives for more robust representations. These advancements have the potential to increase AIGC (Adversarial Image Generation Challenge) and create more efficient technologies.
Foundation Models
Transformer is the backbone architecture for many state-of-the-art models, such as GPT, DALL-E, Codex, and so on.
Traditional models like RNNs had limitations in dealing with variable-length sequences and context. Self-attention mechanism is at the core of the Transformer. Self-attention allows the model to focus on different parts of the input sequence.
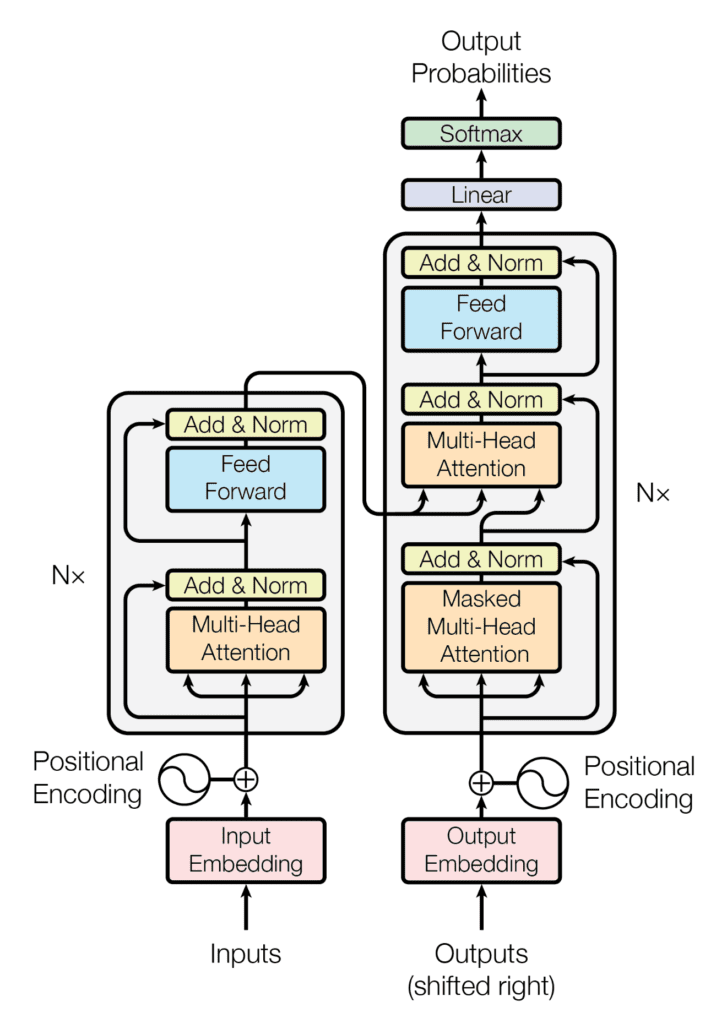
Following is the encoder-decoder structure of the Transformer architecture
Taken from the paper “Attention Is All You Need“.
The encoder processes the input sequence to create the hidden representations whereas the decoder generates the output sequence.
Each encoder and decoder layer includes multi-head attention and feed-forward neural networks. Multi-head attention assigns weights to tokens based on relevance.
The transformer’s inherent parallelizability minimizes inductive biases, making it ideal for large-scale pre-training and adaptability to different downstream tasks.
There are two main types of pre-trained language models based on the training tasks:
1. Masked language modeling (e.g. BERT): Predict masked tokens within a sentence.
2. Autoregressive language modeling (e.g. GPT-3): Predict the next token given previous ones.
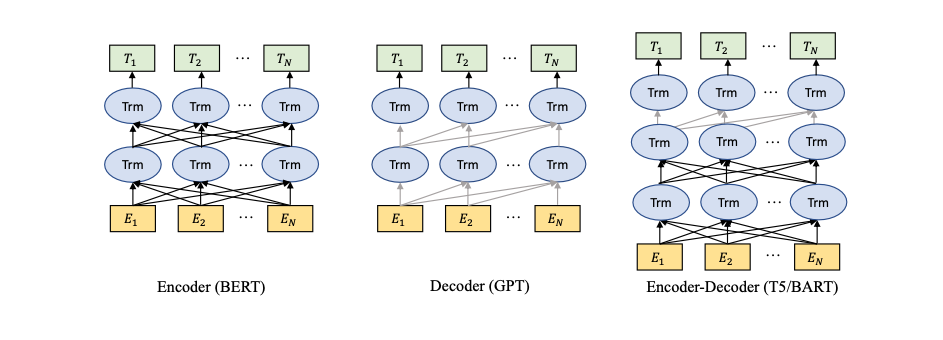
The following are the three main categories of pre-trained models:
1. Encoder models (BERT)
2. Decoder models (GPT)
3. Encoder-decoder models (T5-BART)
References
- https://www.youtube.com/live/Sy1psHS3w3I
- https://llmagents-learning.org/slides/Burak_slides.pdf
- A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT – Link
- https://mallahyari.github.io/rag-ebook/intro.html
- https://arxiv.org/abs/1706.03762
- Speech Recognition on LibriSpeech test-other – Link
- Image Classification on ImageNet – Link