In my previous article, I wrote about why asynchronous processing queues are the backbone of agentic AI. The response was overwhelming—dozens of engineers reached out, saying, "Finally, someone's talking about the real problems."
Here's the thing: we're drowning in content about prompt engineering and which framework to use. But if you've tried to move an agent from a Jupyter notebook to production, you know the real battle isn't getting an LLM to follow instructions. It's everything that comes after.
It's 3 AM, and your agent workflow has been stuck for six hours because of a rate limit you didn't anticipate. It's explaining to your CTO why the agent "forgot" the context from yesterday's session. It's watching your AWS bill climb because your agents are calling GPT-4 in an infinite loop.
These aren't edge cases. They're the norm. And nobody's writing about them.
The Problem with Most Agentic AI Content
Most articles on agentic AI follow the same pattern: here's how to build a simple agent, here's how to chain a few tools together, here's the latest framework that will solve everything. But production systems don't care about your framework. They care about reliability, cost, observability, and maintainability.
I've spent quite some time now building production agentic systems, and I've learned something important: the challenges of production agentic AI are fundamentally distributed systems problems—with the added complexity of non-deterministic AI behavior. You're not just dealing with network failures and race conditions. You're dealing with hallucinations, token limits, and an "intelligent" system that might decide to do something completely unexpected.
This series is about the infrastructure and architectural patterns that separate demos from production-ready systems. The stuff that matters when your agent needs to run 24/7, handle failures gracefully, and scale beyond a few test users.
What I'll Be Covering
Over the next few weeks, I'm diving deep into the topics that keep me up at night (and probably you, too, if you're building this stuff for real).
State Management and Context Continuity in Multi-Agent Systems
Your agent needs memory. Not just for the current task, but across sessions, across failures, and across restarts. Think about it: a customer service agent who forgets every conversation after 10 minutes isn't useful. But how do you maintain context when your LLM has a fixed context window? How do you persist the state when the agent crashes mid-workflow?
We'll explore memory architectures that actually work in production—short-term vs long-term memory, context window mitigation strategies, and the eternal debate: should your agents be stateless or stateful? Spoiler: it depends, and I'll show you exactly on what.
Agent Orchestration vs Choreography: Choosing the Right Coordination Pattern
Here's where it gets interesting. You have multiple agents that need to work together. Do you use a central orchestrator that directs traffic? Or do you let agents communicate through events in a choreographed dance?
Most people default to orchestration because it feels safer—you have control. But choreography scales better and is more resilient. The truth? You probably need both, and knowing when to use which pattern is the difference between a system that scales and one that collapses under its own complexity.
We'll look at real coordination patterns: supervisor agents, event-driven architectures, hybrid approaches, and the trade-offs that actually matter—consistency vs autonomy, latency vs throughput, and simplicity vs flexibility.
Reliability and Fault Tolerance in Agentic Workflows
This is the unsexy stuff that nobody wants to write about, but everyone needs. What happens when the LLM times out? When do you hit a rate limit? When your agent hallucinates and calls the wrong API? When does the entire workflow need to be rolled back?
Production systems need answers. We'll cover retry strategies, dead letter queues for failed tasks, circuit breakers for external integrations, and compensating transactions when things go wrong. Plus, the monitoring and observability patterns let you sleep at night.
Because here's the hard truth: your agents will fail. The question is whether you've built systems that handle failure gracefully or catastrophically.
Data Foundations: The Standardization Challenge Nobody's Solving
Agents are only as good as the data they can access. But enterprise data is a mess—different schemas, inconsistent formats, and tribal knowledge locked in people's heads. How do you prepare your data infrastructure for agents that need to access everything?
We'll explore data quality requirements, schema design patterns, and the emerging standards (like MCP), trying to solve this. Because the bottleneck in most agentic systems isn't the AI—it's getting the AI access to clean, structured data.
Tool Integration Patterns: How Agents Actually Talk to Your Systems
Function calling sounds simple in a tutorial. Connect your agent to an API, and magic happens. But in production? You're dealing with authentication, rate limits, partial failures, data transformation, and the question of how much autonomy to give your agents.
Should your agent be able to delete data? Approve transactions? Send emails to customers? We'll look at the patterns that make tool integration safe and scalable, including API design for agents, permission models, and the emerging standards trying to standardize this chaos.
Cost Optimization: Keeping Your Agent System from Bankrupting You
Let's talk money. Running production agents is expensive. Every LLM call costs money. Every tool invocation costs money. And if your agent gets stuck in a loop or you're using GPT-4 when GPT-3.5 would work fine, costs spiral fast.
I'll share strategies for model routing (when to use which model), configuration optimization, caching patterns, and the observability you need to understand where your money is actually going.
The Bigger Picture: Layers of the Agentic Stack
These topics aren't isolated problems. They're interconnected layers of a complete system:
Layer 1: Infrastructure—Asynchronous processing, queues, message passing (covered in my previous article)
Layer 2: State & Memory—How agents remember and maintain context
Layer 3: Coordination—How multiple agents work together
Layer 4: Reliability—How the system handles failures and stays operational
Layer 5: Integration—How agents connect to your existing systems and data
Each layer builds on the previous one. You can't solve orchestration without understanding state management. You can't build reliable systems without proper infrastructure. It's a stack, and every layer matters.
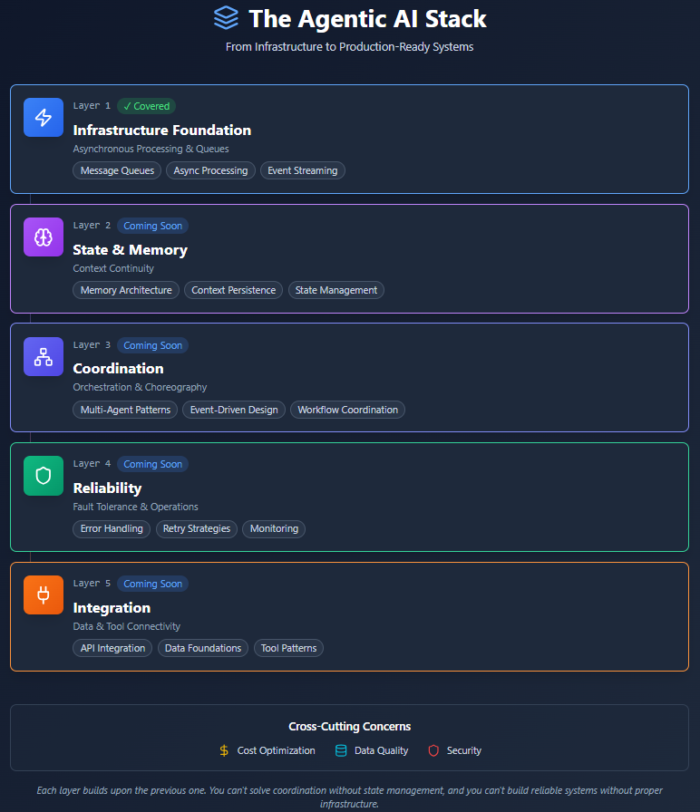
Figure 1: The Agentic AI Stack
Why This Matters Now
We're at an inflection point. The first wave of agentic AI was about proving it could work. The second wave—the one we're in now—is about making it work reliably at scale. Companies are moving from experiments to production deployments, and they're hitting all these problems at once.
The frameworks will keep evolving. The models will keep improving. But the fundamental challenges of building distributed, reliable, autonomous systems? Those aren't going away. If anything, they're getting harder as we build more ambitious multi-agent systems.
Let's Build This Together
I'm not claiming to have all the answers. Some of these problems are still unsolved. Some have solutions that work in one context but fail in another. What I'm sharing is what I've learned in the trenches—the patterns that worked, the mistakes that cost me days of debugging, and the questions I'm still wrestling with.
I want this to be a conversation. If you're building production agentic systems, you have war stories. You've hit problems I haven't thought of. You've found solutions I should know about.
So here's my ask: which of these topics hits closest to home for you? What's keeping you up at night? What would you want me to dive into first?
Drop a comment, send me a message, or just follow along. Over the next few weeks, we're going deep on each of these topics. Real code, real architectures, real trade-offs.
Let's figure this out together.
This is part of an ongoing series on building production-ready agentic AI systems. Read the previous article: Why Asynchronous Processing Queues Are the Backbone of Agentic AI
Related Articles
- Agent Building Blocks: Build Production-Ready AI Agents with LangChain | Complete Developer Guide
- Building Agents That Remember: State Management in Multi-Agent AI Systems
- Building Production-Ready AI Agents with LangGraph: A Developer's Guide to Deterministic Workflows
- LLM-Powered Chatbots: A Practical Guide to User Input Classification and Intent Handling
Follow for more technical deep dives on AI/ML systems, production engineering, and building real-world applications: