Learning Outcome
In this post, we will learn about:
-
What is Ollama?
-
How do you install the Llama model using the Ollama framework?
-
Running Llama models
-
Different ways to access the Ollama model
-
Access the deployed models using Page Assist plugin in the Web Browsers
-
Access the Llama model using HTTP API in Python Language
-
Access the Llama model using the Langchain Library
-
1. What is Ollama?
Ollama is an open-source tool/framework that facilitates users in running large language models (LLMs) on their local computers, such as PCs, edge devices like Raspberry Pi, etc.
2. How to install it?
Visit https://ollama.com/download. You can download and install it based on your PC's OS, such as Mac, Linux, and Windows.
3. Running Llama 3.2
Five versions of Llama 3.2 models are available: 1B, 3B, 11B, and 90B. 'B' indicates billions. For example, 1B means that the model has been trained on 1 billion parameters. 1B and 3B are text-only models, whereas 11B and 90B are multimodal (text and images).
Run 1B model: ollama run llama3.2:1b
Run 3B model: ollama run llama3.2
After running these models on the terminal, we can interact with the model using the terminal.
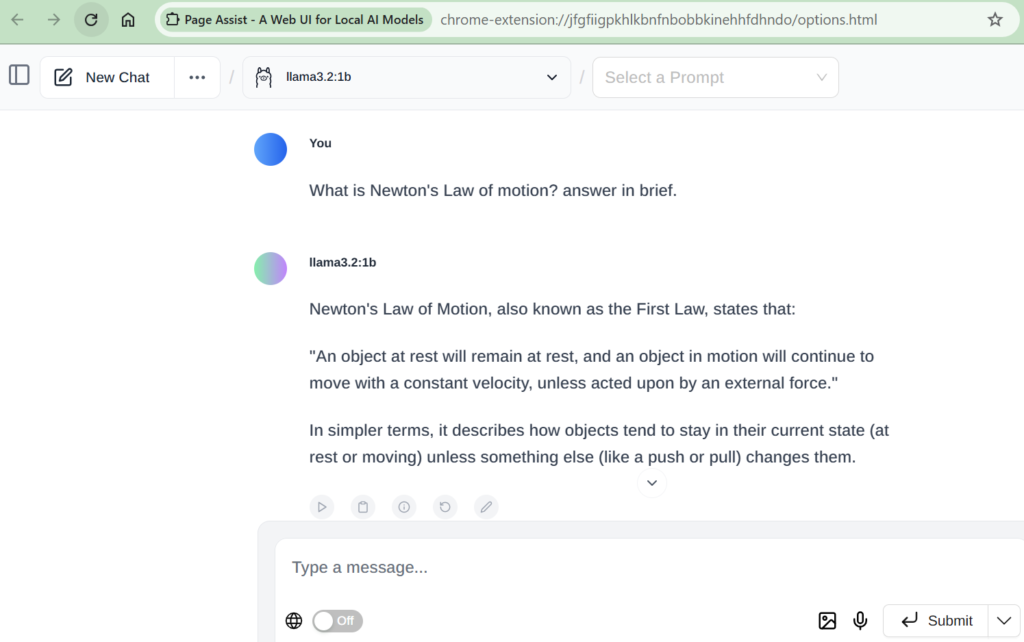
4. Access the deployed models using Web Browsers
Page Assist is an open-source browser extension that provides a sidebar and web UI for your local AI model. It allows you to interact with your model from any webpage.
5. Access the Llama model using HTTP API in Python Language
Before running the following code, you should have performed steps 1 and 2 mentioned above. That is, you have installed Ollama, and you are running the Llama model under the Ollama environment. When you run the Llama under Ollama, it provides access to the model in the following two ways: 1) through the command line and 2) through an HTTP API on port 11434. The following code is nothing but Python code for accessing the model through the HTTP API.
import jsonimport requestsdata = '{}'data = json.loads(data)data["model"] = "llama3.2:1b"data["stream"] = Falsedata["prompt"] = "What is Newton's law of motion?" + " Answer in short."# Sent to Chatbotr = requests.post('http://127.0.0.1:11434/api/generate', json=data)response_data = json.loads(json.dumps(r.json()))# Print User and Bot Messageprint(f'\nUser: {data["prompt"]}')bot_response = response_data['response']print(f'\nBot: {bot_response}')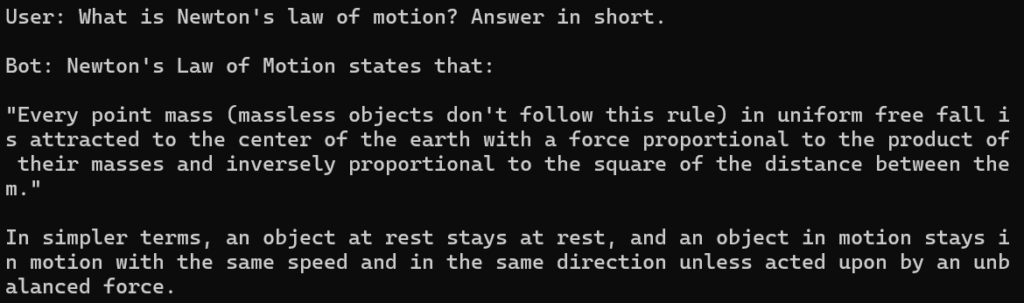
6. Access the Llama model using the Langchain Library
Dependent library installation: pip install langchain-ollama
from langchain_ollama.llms import OllamaLLMfrom langchain_core.prompts import ChatPromptTemplatequery = "What is Newton's law of motion?"template = """Instruction: {instruction}Query: {query}"""prompt = ChatPromptTemplate.from_template(template)model = OllamaLLM(model="llama3.2") # Using llama3.2 as llm modelchain = prompt | modelbot_response = chain.invoke({"instruction": "Answer the question. If you cannot answer the question, answer with \"I don't know.\"", "query": query })print(f'\nUser: {query}')print(f'\nBot: {bot_response}')
7. Running ollama for remote access
By default, the Ollama service runs locally and is not accessible remotely. To make Ollama remotely accessible, we need to set the following environment variables:
OLLAMA_HOST=0.0.0.0 OLLAMA_ORIGINS=*
Related Articles
- Question Answer Chatbot using RAG, Llama and Qdrant
- Making a talking bot using Llama3.2:1b running on Raspberry Pi 4 Model-B 4GB
- Reranking for RAG: Boosting Answer Quality in Retrieval-Augmented Generation
- ChatML Guide: Master Structured Prompts for LLMs
Follow for more technical deep dives on AI/ML systems, production engineering, and building real-world applications:


