In Part 2, we built a ProvenanceTracker that generates signed, schema-versioned lineage logs for datasets, models, and inferences. That ensures trust at the data level — but provenance becomes truly valuable when we can query and reason about it.
In this post, we’ll import the signed logs into Neo4j, the leading graph database, and show how to query provenance directly using Cypher.
Why Neo4j for Provenance?
AI lineage is fundamentally a graph:
-
A
Datasetcan be used to train manyModels. -
A
Modelcan generate thousands ofInferences. -
An
Inferencemust be traceable back to the model and dataset(s).
Representing this as a graph gives us a natural way to answer questions like:
-
“Which datasets were used to train this model?”
-
“Which inferences came from this model version?”
-
“What is the complete lineage of an inference?”
Step 1. Provenance Importer with Signature Verification
The importer reads signed JSONL logs, verifies signatures, and inserts data into Neo4j with constraints.
# ProvenanceImporter.pyimport jsonimport base64from typing import Dict, Anyfrom cryptography.hazmat.primitives import hashesfrom cryptography.hazmat.primitives.asymmetric import paddingfrom cryptography.hazmat.primitives.serialization import load_pem_public_keyfrom neo4j import GraphDatabaseEXPECTED_SCHEMA = "1.1"class ProvenanceImporter: def __init__(self, uri, user, password, public_key_path: str): self.driver = GraphDatabase.driver(uri, auth=(user, password)) # Load public key for verifying signatures with open(public_key_path, "rb") as f: self.public_key = load_pem_public_key(f.read()) def close(self): self.driver.close() def _verify_signature(self, signed_data: str, signature_b64: str) -> bool: try: signature = base64.b64decode(signature_b64) self.public_key.verify( signature, signed_data.encode("utf-8"), padding.PSS( mgf=padding.MGF1(hashes.SHA256()), salt_length=padding.PSS.MAX_LENGTH, ), hashes.SHA256(), ) return True except Exception: return False def _validate_jsonl(self, jsonl_path: str): """ Validate schema + signatures before import. Returns list of verified payloads (dicts). """ valid_records = [] with open(jsonl_path, "r") as f: for line_no, line in enumerate(f, start=1): try: envelope = json.loads(line.strip()) except json.JSONDecodeError: raise ValueError(f"Line {line_no}: invalid JSON") schema = envelope.get("schema_version") signed_data = envelope.get("signed_data") signature = envelope.get("signature") if schema != EXPECTED_SCHEMA: raise ValueError(f"Line {line_no}: schema version mismatch ({schema})") if not signed_data or not signature: raise ValueError(f"Line {line_no}: missing signed_data/signature") if not self._verify_signature(signed_data, signature): raise ValueError(f"Line {line_no}: signature verification failed") # Verified, safe to parse valid_records.append(json.loads(signed_data)) return valid_records def import_from_jsonl(self, jsonl_path: str): # Validate before importing print("🔍 Validating provenance log file...") valid_records = self._validate_jsonl(jsonl_path) print(f"✅ Validation successful: {len(valid_records)} records") with self.driver.session() as session: self._ensure_constraints(session) for record in valid_records: self._process_record(session, record) def _process_record(self, session, record: Dict[str, Any]): if record["type"] == "dataset": session.run( """ MERGE (d:Dataset {hash: $hash}) SET d.path = $path, d.description = $desc, d.timestamp = $ts """, hash=record["hash"], path=record["path"], desc=record.get("description", ""), ts=record["timestamp"], ) elif record["type"] == "model": session.run( """ MERGE (m:Model {name: $name, commit: $commit}) SET m.hyperparameters = $hyperparams, m.environment = $env, m.timestamp = $ts """, name=record["model_name"], commit=record.get("git_commit", "N/A"), hyperparams=json.dumps(record.get("hyperparameters", {})), env=json.dumps(record.get("environment", {})), ts=record["timestamp"], ) # Multiple dataset links for d_hash in record.get("dataset_hashes", []): session.run( """ MATCH (d:Dataset {hash: $hash}) MATCH (m:Model {name: $name}) MERGE (d)-[:USED_IN]->(m) """, hash=d_hash, name=record["model_name"], ) elif record["type"] == "inference": session.run( """ MERGE (i:Inference {id: $id}) SET i.input = $input, i.output = $output, i.timestamp = $ts WITH i MATCH (m:Model {name: $name}) MERGE (m)-[:GENERATED]->(i) """, id=record.get("id"), name=record["model_name"], input=json.dumps(record.get("input", {})), output=json.dumps(record.get("output", {})), ts=record["timestamp"], ) def _ensure_constraints(self, session): """Create uniqueness constraints (idempotent).""" session.run("CREATE CONSTRAINT IF NOT EXISTS FOR (d:Dataset) REQUIRE d.hash IS UNIQUE") session.run("CREATE CONSTRAINT IF NOT EXISTS FOR (m:Model) REQUIRE (m.name, m.commit) IS UNIQUE") session.run("CREATE CONSTRAINT IF NOT EXISTS FOR (i:Inference) REQUIRE i.id IS UNIQUE")# ---------------------------# Example usage# ---------------------------if __name__ == "__main__": importer = ProvenanceImporter( "bolt://localhost:7687", "neo4j", "password@1234", "public_key.pem" ) try: importer.import_from_jsonl("provenance_logs.jsonl") print("✅ Imported signed provenance logs into Neo4j with constraints") except Exception as e: print(f"❌ Import aborted: {e}") finally: importer.close()Step 2. Running Neo4j and Importer
-
Start Neo4j via Docker:
docker run --publish=7474:7474 --publish=7687:7687 neo4j:latest -
Access the Neo4j Browser at http://localhost:7474
Default user/pass:neo4j/neo4j(change the password after first login). -
Run the importer:
python ProvenanceImporter.py
Step 3. Querying Provenance with Cypher
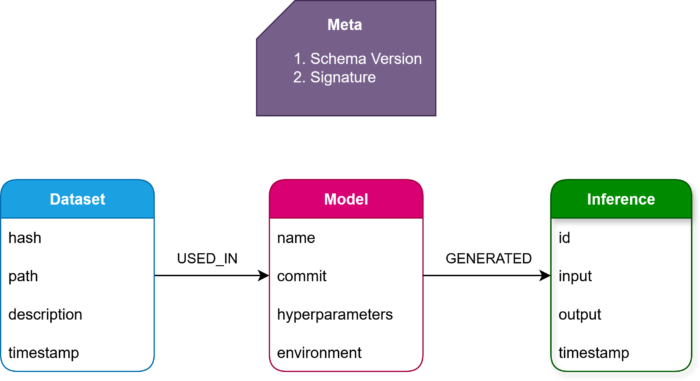
Fig: Schema Diagram
3.1 List all datasets
MATCH (d:Dataset)RETURN d.hash AS hash, d.path AS path, d.description AS description, d.timestamp AS logged_atORDER BY logged_at DESC;
3.2 List all models and their hyperparameters
MATCH (m:Model)RETURN m.name AS model, m.commit AS git_commit, m.hyperparameters AS hyperparams, m.environment AS env, m.timestamp AS logged_atORDER BY logged_at DESC;
3.3 Show which datasets were used for each model
MATCH (d:Dataset)-[:USED_IN]->(m:Model)RETURN d.hash AS dataset_hash, d.path AS dataset_path, m.name AS model, m.commit AS commitORDER BY model;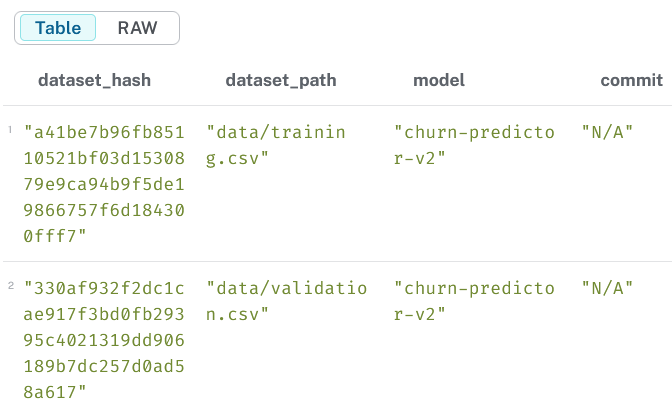
3.4 List all inferences with input/output
MATCH (m:Model)-[:GENERATED]->(i:Inference)RETURN i.id AS inference_id, m.name AS model, i.input AS input_data, i.output AS output_data, i.timestamp AS tsORDER BY ts DESC;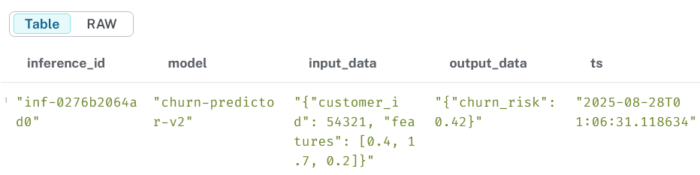
3.5 Full provenance lineage (dataset → model → inference)
MATCH (d:Dataset)-[:USED_IN]->(m:Model)-[:GENERATED]->(i:Inference)RETURN d.hash AS dataset_hash, m.name AS model, i.id AS inference_id, i.timestamp AS tsORDER BY ts DESC;
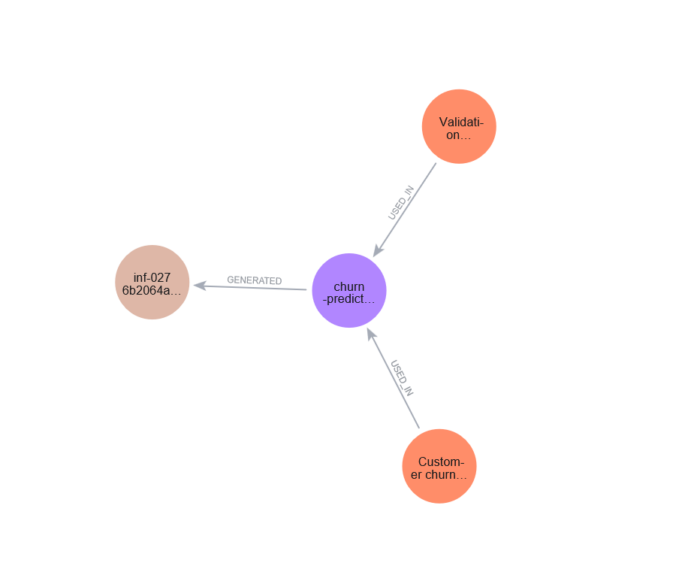
3.6 Visualize provenance graph
MATCH (d:Dataset)-[:USED_IN]->(m:Model)-[:GENERATED]->(i:Inference)RETURN d, m, i;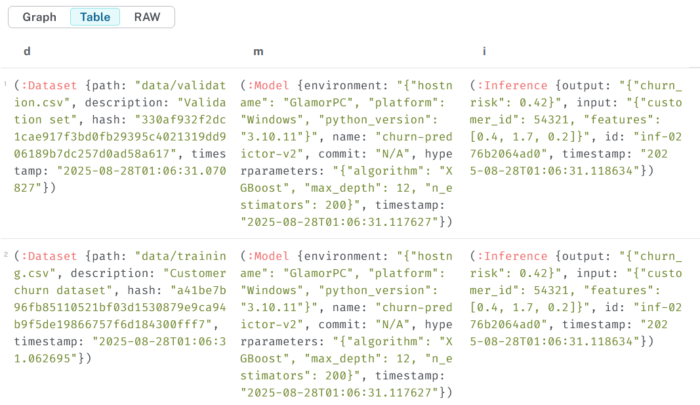
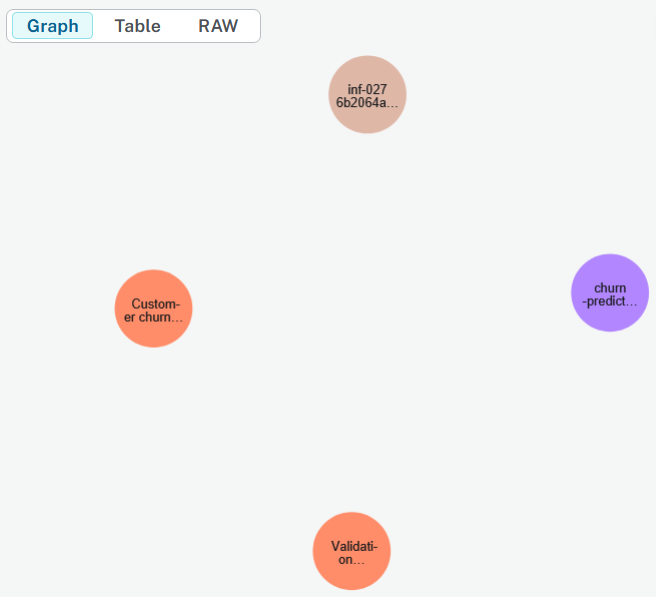
👉 Run this in Neo4j Browser and click the graph view (circle-node visualization).
You’ll see the chain of custody: Datasets → Models → Inferences.
3.7 Find models trained on multiple datasets
MATCH (m:Model)<-[:USED_IN]-(d:Dataset)WITH m, collect(d.hash) AS datasetsWHERE size(datasets) > 1RETURN m.name AS model, datasets, size(datasets) AS dataset_count;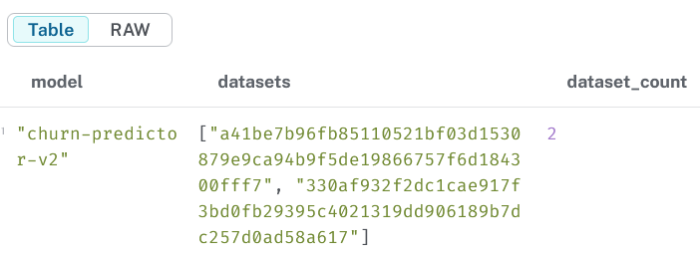
3.8 Check if all models have dataset provenance
MATCH (m:Model)WHERE NOT (m)<-[:USED_IN]-(:Dataset)RETURN m.name AS model_without_provenance;No changes, no records
⚡ With these queries, you can:
-
Audit which dataset versions were used
-
Trace from inference results back to datasets
-
Verify reproducibility and compliance
What We Achieved
By combining signed JSONL provenance logs with Neo4j:
-
Schema constraints ensure data integrity.
-
Every record is tamper-resistant (signatures verified before import).
-
Relationships are explicit (
USED_IN,GENERATED). -
Provenance queries are expressive (thanks to Cypher).
✅ Takeaway: With Neo4j as the provenance store, AI engineers can query, audit, and explain the complete lineage of any model or inference — a vital step toward trustworthy and compliant AI systems.
Related Articles
- Provenance in AI: Auto-Capturing Provenance with MLflow and W3C PROV-O in PyTorch Pipelines – Part 4
- Provenance in AI: Tracking AI Lineage with Signed Provenance Logs in Python - Part 2
- Provenance in AI: Why It Matters for AI Engineers - Part 1
Follow for more technical deep dives on AI/ML systems, production engineering, and building real-world applications: