Cross-Encoders: The Missing Piece in Your RAG Pipeline
Introduction
You've built a RAG system. Your embedding search returns 100 candidates in milliseconds. But here's the problem: the most relevant answer is stuck at position 47, and your users are seeing mediocre results ranked 1-10.
Sound familiar?
This isn't a theoretical problem. In production RAG systems, the gap between "retrieved" and "actually relevant" can make or break user trust. Cross-encoders solve this—but they come with trade-offs you need to understand before adding them to your stack.
What Cross-Encoders Actually Do
A cross-encoder takes your query and a candidate document, feeds them both into a transformer, and outputs a single relevance score. Unlike bi-encoders that encode query and document separately, cross-encoders let every token in your query attend to every token in the document.
Simple analogy: Bi-encoders are like comparing movie descriptions by reading summaries separately. Cross-encoders actually watch both movies side-by-side and spot the nuanced differences.
The Input Format
[CLS] How do I recycle lithium batteries safely? [SEP] Lithium-ion batteries require thermal pre-treatment before recycling to prevent combustion. [SEP][CLS] How do I recycle lithium batteries safely? [SEP] Lithium-ion batteries require thermal pre-treatment before recycling to prevent combustion. [SEP]The model processes this as one sequence, allowing full attention between query tokens ("safely", "recycle") and document tokens ("thermal pre-treatment", "combustion").
Why Bi-Encoders Aren't Enough
Bi-encoders excel at retrieval speed. Encode your corpus once, store the vectors, and search with cosine similarity. Fast. Scalable. But here's what they miss:
1. Negations
-
Query: "treatments that don't require surgery"
-
Bi-encoder might rank "surgical treatments" high because of token overlap
-
Cross-encoder understands the negation context
2. Comparative Questions
-
Query: "difference between REST and GraphQL"
-
Bi-encoder: ranks documents mentioning either term
-
Cross-encoder: prioritizes comparative analysis
3. Domain-Specific Phrasing
-
Legal: "Section 5(a)" vs "Clause Five Subsection A"
-
Medical: "MI" vs "myocardial infarction"
-
Cross-encoders learn these equivalences through fine-tuning
Bi-Encoder vs Cross-Encoder: Architecture Comparison
Before diving into cross-encoder internals, let's visualize the fundamental architectural difference:
Bi-Encoder Architecture
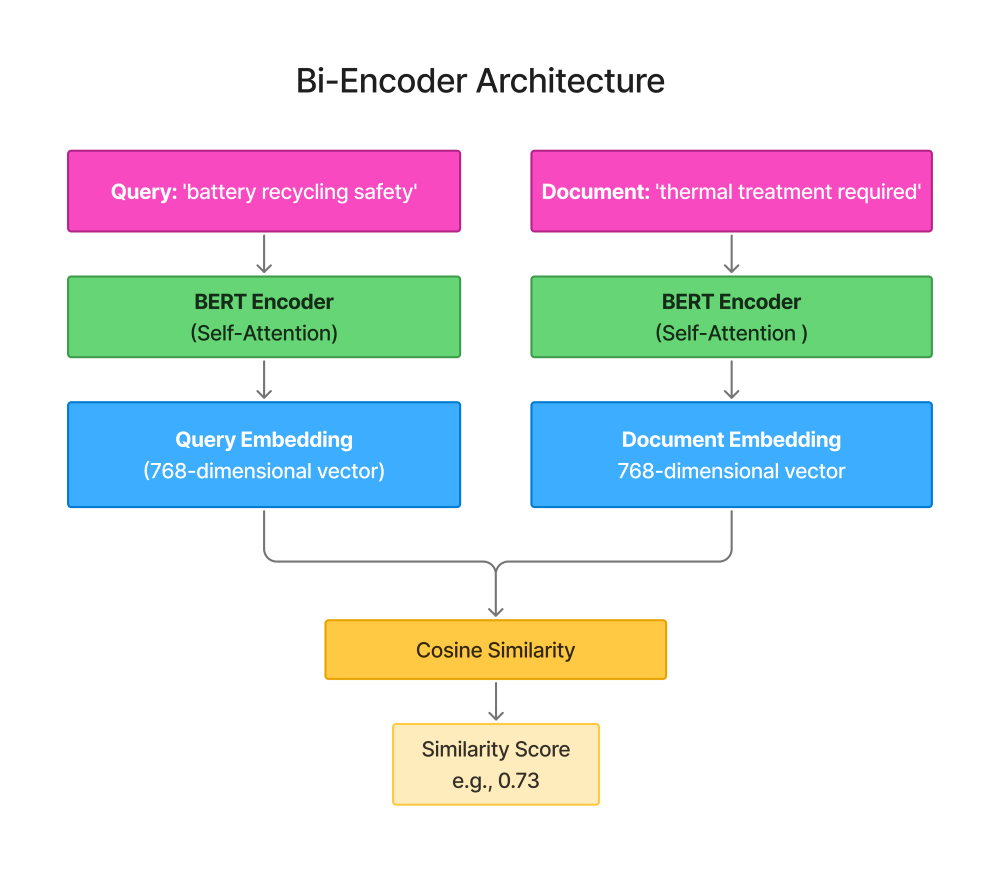
Key characteristics:
-
Query and document encoded independently
-
Each gets its own embedding vector
-
Similarity computed via cosine/dot product
-
Fast: Encode documents once, reuse embeddings
-
Scalable: Billions of documents with vector search (FAISS, Hnswlib)
Cross-Encoder Architecture
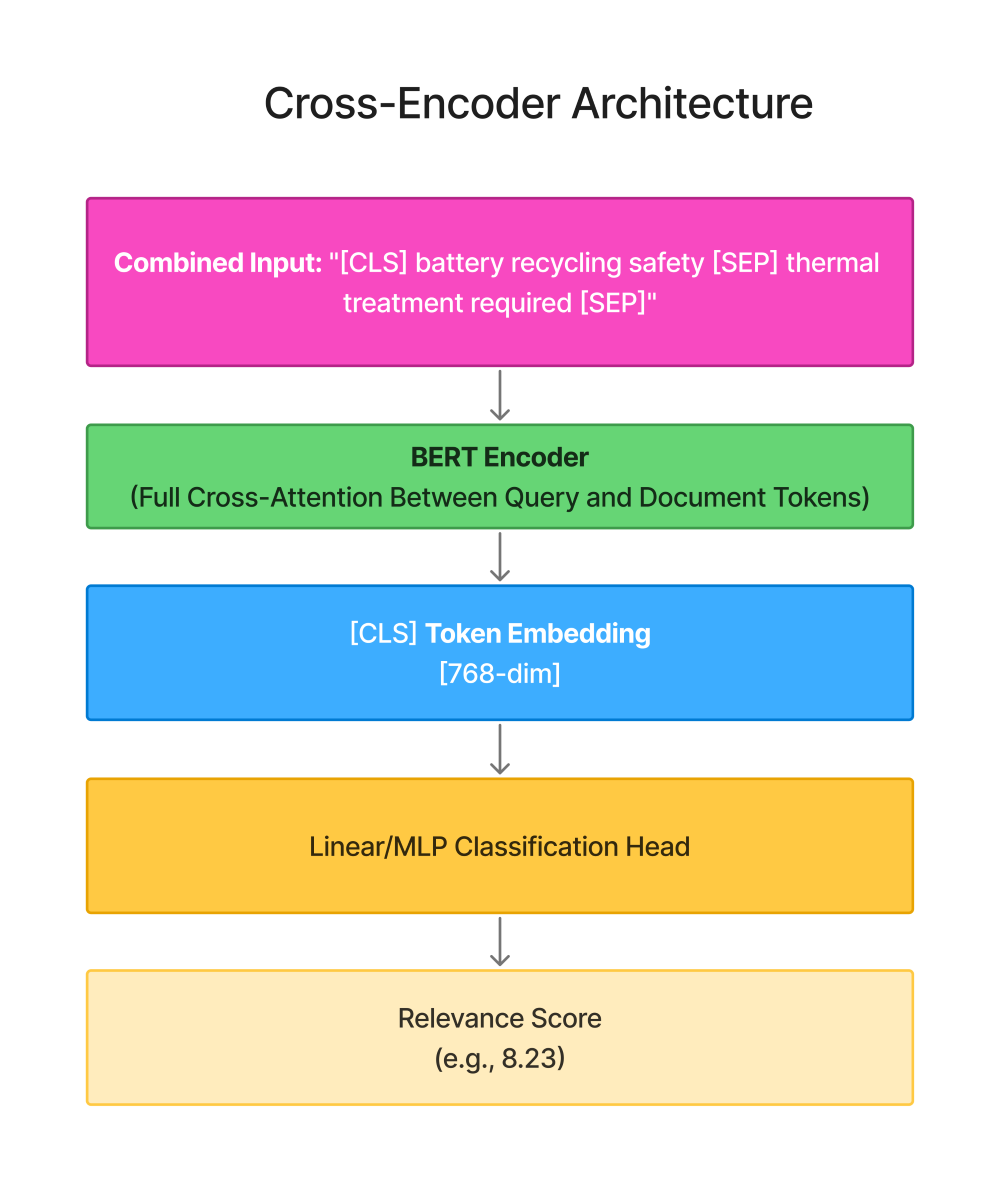
Key characteristics:
-
Query and document in single encoding pass
-
Tokens attend to each other (cross-attention)
-
[CLS] token aggregates the interaction
-
Slow: Must re-encode every query-document pair
-
Precise: Captures nuanced relationships
Visual Comparison
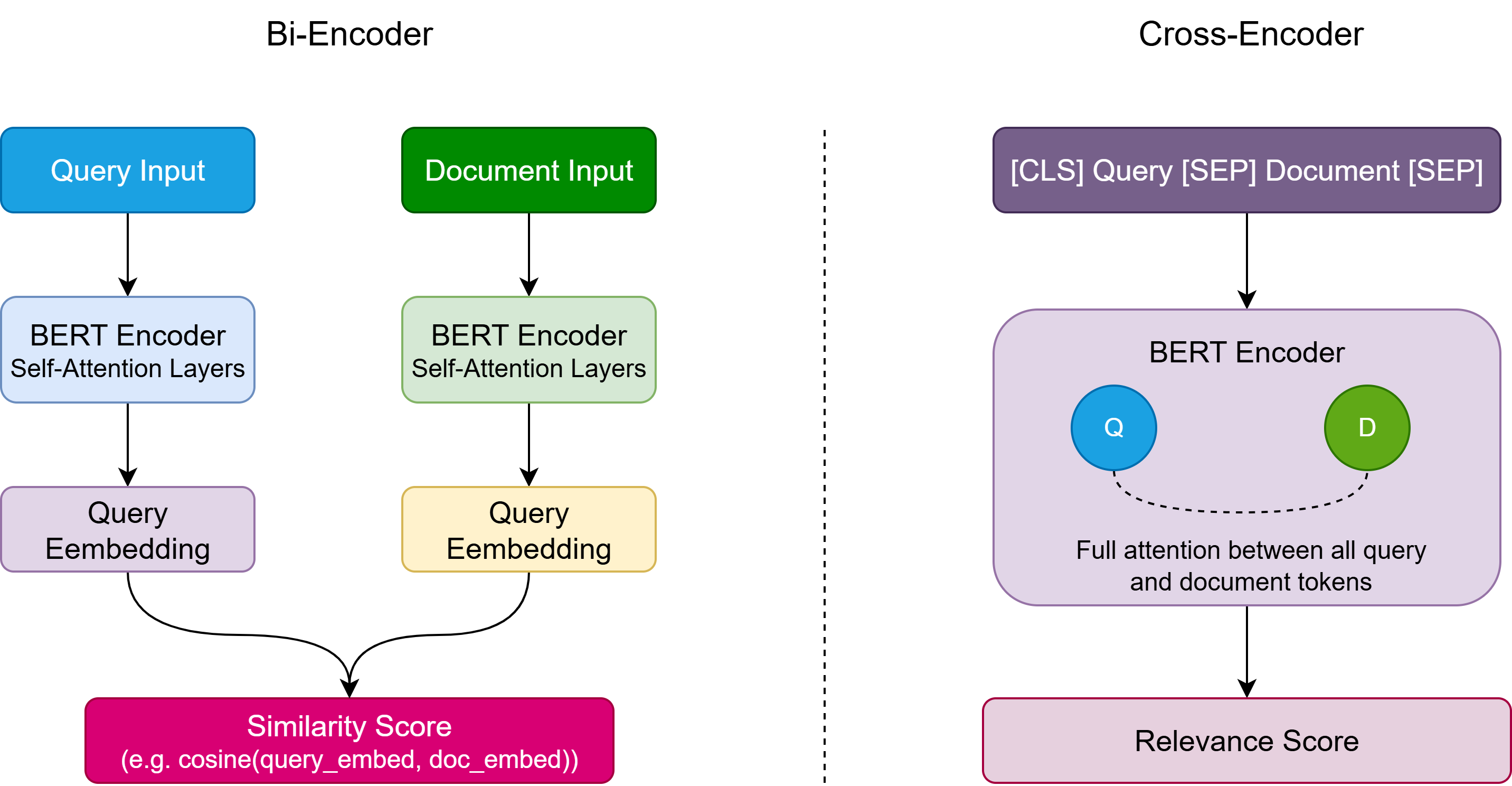
The Critical Difference: Attention Patterns
Bi-Encoder:
python
# Query tokens only attend to other query tokens"battery" attends to: ["battery", "recycling", "safety"]<div></div># Document tokens only attend to other document tokens "thermal" attends to: ["thermal", "treatment", "required"]<div></div># No interaction until similarity computation# Query tokens only attend to other query tokens"battery" attends to: ["battery", "recycling", "safety"]# Document tokens only attend to other document tokens "thermal" attends to: ["thermal", "treatment", "required"]# No interaction until similarity computationCross-Encoder:
python
# Query tokens attend to BOTH query and document tokens"battery" attends to: ["battery", "recycling", "safety", "thermal", "treatment", "required"]<div></div># Document tokens also attend to query tokens"thermal" attends to: ["battery", "recycling", "safety", "thermal", "treatment", "required"]<div></div># Rich interaction from layer 1# Query tokens attend to BOTH query and document tokens"battery" attends to: ["battery", "recycling", "safety", "thermal", "treatment", "required"]# Document tokens also attend to query tokens"thermal" attends to: ["battery", "recycling", "safety", "thermal", "treatment", "required"]# Rich interaction from layer 1Speed vs Precision Trade-off
| Aspect | Bi-Encoder | Cross-Encoder |
|---|---|---|
| Encoding | Once per document | Once per query-doc pair |
| 1M docs, 1 query | 1M + 1 = 1M encodings | 1M × 1 = 1M encodings |
| 1M docs, 1K queries | 1M + 1K encodings | 1M × 1K = 1B encodings |
| Latency (1 query) | ~15ms | ~800ms (100 candidates) |
| Best for | Initial retrieval | Final re-ranking |
This is why you combine both in production:
-
Bi-encoder: Retrieve top 100 from 1M documents (~15ms)
-
Cross-encoder: Rerank those 100 candidates (~120ms on GPU)
-
Total: ~135ms for high-quality results
Cross-Encoder Architecture Deep Dive
Here's what happens inside a cross-encoder:
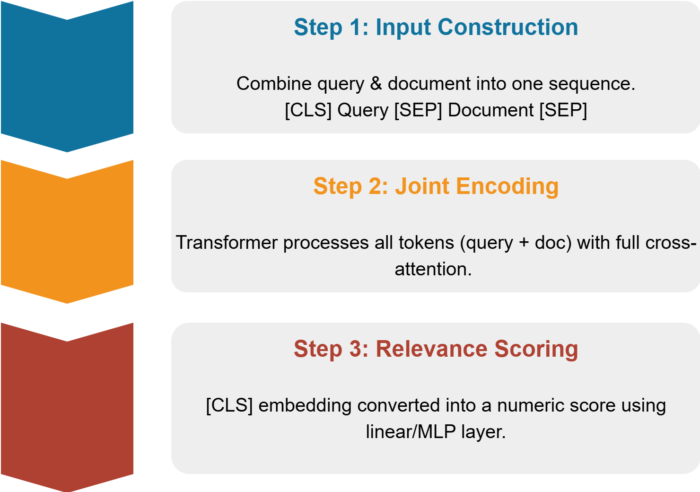
Step 1: Input Construction
Concatenate query and document with special tokens:
[CLS] + query_tokens + [SEP] + document_tokens + [SEP][CLS] + query_tokens + [SEP] + document_tokens + [SEP]Step 2: Joint Encoding
The entire sequence passes through BERT/RoBERTa/DeBERTa layers. Unlike bi-encoders where query and document live in separate encoding passes, here they interact from layer one.
What this enables:
-
Token "battery" in query attends to "lithium-ion" in document
-
Model learns "recycling" → "processed" → "reduce hazards" semantic chains
-
Attention patterns capture causal relationships
Step 3: Relevance Scoring
Extract the [CLS] token's final embedding:
cls_embedding = transformer_output[0] # Shape: [768] for BERT-baserelevance_score = linear_layer(cls_embedding) # Shape: [1]cls_embedding = transformer_output[0] # Shape: [768] for BERT-baserelevance_score = linear_layer(cls_embedding) # Shape: [1]For classification tasks: softmax over labels (relevant/not-relevant). For regression: direct score output (0.0 - 1.0).
Implementation: From Theory to Production
Basic Scoring
from sentence_transformers import CrossEncoderfrom typing import List, Tupleimport numpy as np<div></div>def score_documents( query: str, documents: List[str], model_name: str = 'cross-encoder/ms-marco-MiniLM-L-6-v2') -> List[Tuple[str, float]]: """ Score documents against a query using cross-encoder. Args: query: Search query string documents: List of candidate documents model_name: HuggingFace model identifier Returns: List of (document, score) tuples sorted by relevance """ model = CrossEncoder(model_name) # Create query-document pairs pairs = [(query, doc) for doc in documents] # Batch scoring for efficiency scores = model.predict(pairs, batch_size=32, show_progress_bar=False) # Combine and sort results = list(zip(documents, scores)) results.sort(key=lambda x: x[1], reverse=True) return results<div></div># Example usagequery = "What are the safety protocols for lithium battery recycling?"docs = [ "Lithium-ion batteries require thermal pre-treatment to prevent combustion during recycling.", "Solar panels have a 25-year operational lifespan in most climates.", "Battery recycling programs reduce environmental impact significantly."]<div></div>ranked = score_documents(query, docs)for doc, score in ranked: print(f"[{score:.4f}] {doc}")from sentence_transformers import CrossEncoderfrom typing import List, Tupleimport numpy as npdef score_documents( query: str, documents: List[str], model_name: str = 'cross-encoder/ms-marco-MiniLM-L-6-v2') -> List[Tuple[str, float]]: """ Score documents against a query using cross-encoder. Args: query: Search query string documents: List of candidate documents model_name: HuggingFace model identifier Returns: List of (document, score) tuples sorted by relevance """ model = CrossEncoder(model_name) # Create query-document pairs pairs = [(query, doc) for doc in documents] # Batch scoring for efficiency scores = model.predict(pairs, batch_size=32, show_progress_bar=False) # Combine and sort results = list(zip(documents, scores)) results.sort(key=lambda x: x[1], reverse=True) return results# Example usagequery = "What are the safety protocols for lithium battery recycling?"docs = [ "Lithium-ion batteries require thermal pre-treatment to prevent combustion during recycling.", "Solar panels have a 25-year operational lifespan in most climates.", "Battery recycling programs reduce environmental impact significantly."]ranked = score_documents(query, docs)for doc, score in ranked: print(f"[{score:.4f}] {doc}")Output:
[8.2341] Lithium-ion batteries require thermal pre-treatment to prevent combustion during recycling.[2.1089] Battery recycling programs reduce environmental impact significantly.[-7.3421] Solar panels have a 25-year operational lifespan in most climates.[8.2341] Lithium-ion batteries require thermal pre-treatment to prevent combustion during recycling.[2.1089] Battery recycling programs reduce environmental impact significantly.[-7.3421] Solar panels have a 25-year operational lifespan in most climates.Production Re-Ranking Pipeline
Here's how cross-encoders fit into a real retrieval system:
from rank_bm25 import BM25Okapifrom sentence_transformers import CrossEncoder, SentenceTransformerimport numpy as npfrom typing import List, Dict, Any<div></div>class HybridRetriever: """ Production-grade retriever combining fast candidate generation with precise cross-encoder re-ranking. """ def __init__( self, corpus: List[str], sparse_weight: float = 0.3, dense_weight: float = 0.3, rerank_weight: float = 0.4, top_k_candidates: int = 100, top_k_rerank: int = 20, top_k_final: int = 5 ): self.corpus = corpus self.sparse_weight = sparse_weight self.dense_weight = dense_weight self.rerank_weight = rerank_weight self.top_k_candidates = top_k_candidates self.top_k_rerank = top_k_rerank self.top_k_final = top_k_final # Initialize retrievers print("Initializing BM25...") tokenized = [doc.lower().split() for doc in corpus] self.bm25 = BM25Okapi(tokenized) print("Initializing bi-encoder...") self.bi_encoder = SentenceTransformer('all-MiniLM-L6-v2') self.doc_embeddings = self.bi_encoder.encode( corpus, show_progress_bar=True, batch_size=64 ) print("Initializing cross-encoder...") self.cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2') def retrieve(self, query: str) -> List[Dict[str, Any]]: """ Hybrid retrieval with cross-encoder re-ranking. Returns: List of dicts with 'text', 'score', and 'rank' keys """ # Stage 1: Fast candidate generation sparse_scores = self._bm25_retrieval(query) dense_scores = self._dense_retrieval(query) # Hybrid fusion (normalized) hybrid_scores = self._normalize_and_fuse(sparse_scores, dense_scores) # Get top candidates top_indices = np.argsort(hybrid_scores)[-self.top_k_candidates:][::-1] candidates = [self.corpus[i] for i in top_indices] # Stage 2: Cross-encoder re-ranking on top candidates rerank_candidates = candidates[:self.top_k_rerank] pairs = [(query, doc) for doc in rerank_candidates] rerank_scores = self.cross_encoder.predict(pairs, batch_size=32) # Combine hybrid + rerank scores final_scores = [] for i, idx in enumerate(top_indices[:self.top_k_rerank]): hybrid_score = hybrid_scores[idx] rerank_score = rerank_scores[i] # Weighted combination final_score = ( (self.sparse_weight + self.dense_weight) * hybrid_score + self.rerank_weight * rerank_score ) final_scores.append((idx, final_score)) # Sort by final score final_scores.sort(key=lambda x: x[1], reverse=True) # Format results results = [] for rank, (idx, score) in enumerate(final_scores[:self.top_k_final], 1): results.append({ 'text': self.corpus[idx], 'score': float(score), 'rank': rank, 'index': int(idx) }) return results def _bm25_retrieval(self, query: str) -> np.ndarray: """Get BM25 scores for all documents.""" tokenized_query = query.lower().split() return self.bm25.get_scores(tokenized_query) def _dense_retrieval(self, query: str) -> np.ndarray: """Get cosine similarity scores using bi-encoder.""" query_embedding = self.bi_encoder.encode(query, show_progress_bar=False) scores = np.dot(self.doc_embeddings, query_embedding) return scores def _normalize_and_fuse( self, sparse_scores: np.ndarray, dense_scores: np.ndarray ) -> np.ndarray: """Min-max normalization and weighted fusion.""" # Normalize to [0, 1] sparse_norm = (sparse_scores - sparse_scores.min()) / (sparse_scores.max() - sparse_scores.min() + 1e-10) dense_norm = (dense_scores - dense_scores.min()) / (dense_scores.max() - dense_scores.min() + 1e-10) # Weighted fusion return self.sparse_weight * sparse_norm + self.dense_weight * dense_norm<div></div># Usage examplecorpus = [ "Lithium-ion batteries require thermal pre-treatment before recycling.", "Solar panel efficiency peaks at 22% for commercial installations.", "Battery recycling reduces carbon footprint by 40% compared to mining.", "Wind turbines generate 3.5 MW in offshore installations.", "Recycling programs for EV batteries are expanding in California.",]<div></div>retriever = HybridRetriever(corpus, top_k_final=3)query = "How should lithium batteries be recycled?"results = retriever.retrieve(query)<div></div>print(f"\nQuery: {query}\n")for result in results: print(f"Rank {result['rank']} [Score: {result['score']:.4f}]") print(f"{result['text']}\n")from rank_bm25 import BM25Okapifrom sentence_transformers import CrossEncoder, SentenceTransformerimport numpy as npfrom typing import List, Dict, Anyclass HybridRetriever: """ Production-grade retriever combining fast candidate generation with precise cross-encoder re-ranking. """ def __init__( self, corpus: List[str], sparse_weight: float = 0.3, dense_weight: float = 0.3, rerank_weight: float = 0.4, top_k_candidates: int = 100, top_k_rerank: int = 20, top_k_final: int = 5 ): self.corpus = corpus self.sparse_weight = sparse_weight self.dense_weight = dense_weight self.rerank_weight = rerank_weight self.top_k_candidates = top_k_candidates self.top_k_rerank = top_k_rerank self.top_k_final = top_k_final # Initialize retrievers print("Initializing BM25...") tokenized = [doc.lower().split() for doc in corpus] self.bm25 = BM25Okapi(tokenized) print("Initializing bi-encoder...") self.bi_encoder = SentenceTransformer('all-MiniLM-L6-v2') self.doc_embeddings = self.bi_encoder.encode( corpus, show_progress_bar=True, batch_size=64 ) print("Initializing cross-encoder...") self.cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2') def retrieve(self, query: str) -> List[Dict[str, Any]]: """ Hybrid retrieval with cross-encoder re-ranking. Returns: List of dicts with 'text', 'score', and 'rank' keys """ # Stage 1: Fast candidate generation sparse_scores = self._bm25_retrieval(query) dense_scores = self._dense_retrieval(query) # Hybrid fusion (normalized) hybrid_scores = self._normalize_and_fuse(sparse_scores, dense_scores) # Get top candidates top_indices = np.argsort(hybrid_scores)[-self.top_k_candidates:][::-1] candidates = [self.corpus[i] for i in top_indices] # Stage 2: Cross-encoder re-ranking on top candidates rerank_candidates = candidates[:self.top_k_rerank] pairs = [(query, doc) for doc in rerank_candidates] rerank_scores = self.cross_encoder.predict(pairs, batch_size=32) # Combine hybrid + rerank scores final_scores = [] for i, idx in enumerate(top_indices[:self.top_k_rerank]): hybrid_score = hybrid_scores[idx] rerank_score = rerank_scores[i] # Weighted combination final_score = ( (self.sparse_weight + self.dense_weight) * hybrid_score + self.rerank_weight * rerank_score ) final_scores.append((idx, final_score)) # Sort by final score final_scores.sort(key=lambda x: x[1], reverse=True) # Format results results = [] for rank, (idx, score) in enumerate(final_scores[:self.top_k_final], 1): results.append({ 'text': self.corpus[idx], 'score': float(score), 'rank': rank, 'index': int(idx) }) return results def _bm25_retrieval(self, query: str) -> np.ndarray: """Get BM25 scores for all documents.""" tokenized_query = query.lower().split() return self.bm25.get_scores(tokenized_query) def _dense_retrieval(self, query: str) -> np.ndarray: """Get cosine similarity scores using bi-encoder.""" query_embedding = self.bi_encoder.encode(query, show_progress_bar=False) scores = np.dot(self.doc_embeddings, query_embedding) return scores def _normalize_and_fuse( self, sparse_scores: np.ndarray, dense_scores: np.ndarray ) -> np.ndarray: """Min-max normalization and weighted fusion.""" # Normalize to [0, 1] sparse_norm = (sparse_scores - sparse_scores.min()) / (sparse_scores.max() - sparse_scores.min() + 1e-10) dense_norm = (dense_scores - dense_scores.min()) / (dense_scores.max() - dense_scores.min() + 1e-10) # Weighted fusion return self.sparse_weight * sparse_norm + self.dense_weight * dense_norm# Usage examplecorpus = [ "Lithium-ion batteries require thermal pre-treatment before recycling.", "Solar panel efficiency peaks at 22% for commercial installations.", "Battery recycling reduces carbon footprint by 40% compared to mining.", "Wind turbines generate 3.5 MW in offshore installations.", "Recycling programs for EV batteries are expanding in California.",]retriever = HybridRetriever(corpus, top_k_final=3)query = "How should lithium batteries be recycled?"results = retriever.retrieve(query)print(f"\nQuery: {query}\n")for result in results: print(f"Rank {result['rank']} [Score: {result['score']:.4f}]") print(f"{result['text']}\n")Performance Trade-offs
Let's be real about the costs:
Latency Benchmarks (100 candidates, single query)
| Stage | Method | Latency | Notes |
|---|---|---|---|
| Retrieval | BM25 | ~5ms | Pre-built index |
| Retrieval | Bi-encoder (ANN) | ~15ms | FAISS/Hnswlib |
| Re-ranking | Cross-encoder (CPU) | ~800ms | Sequential scoring |
| Re-ranking | Cross-encoder (GPU) | ~120ms | Batch size 32 |
Key insight: Cross-encoders are 50-100x slower than bi-encoders. That's why you only apply them to top-k candidates, not your entire corpus.
Memory Footprint
# Model size comparison (FP32)ms-marco-MiniLM-L-6-v2: 90 MB # Cross-encoderall-MiniLM-L6-v2: 80 MB # Bi-encoderms-marco-MiniLM-L-12-v2: 130 MB # Larger cross-encoderbge-reranker-large: 1.2 GB # Best accuracy, heavy# Model size comparison (FP32)ms-marco-MiniLM-L-6-v2: 90 MB # Cross-encoderall-MiniLM-L6-v2: 80 MB # Bi-encoderms-marco-MiniLM-L-12-v2: 130 MB # Larger cross-encoderbge-reranker-large: 1.2 GB # Best accuracy, heavyScaling Strategies
1. Reduce Rerank Candidates
# Instead of reranking top-100top_k_rerank = 100 # Latency: ~800ms<div></div># Rerank only top-20top_k_rerank = 20 # Latency: ~160ms# Instead of reranking top-100top_k_rerank = 100 # Latency: ~800ms# Rerank only top-20top_k_rerank = 20 # Latency: ~160ms2. Batch Processing
# Sequential (slow)for pair in pairs: score = model.predict([pair]) # Multiple GPU calls<div></div># Batched (fast)scores = model.predict(pairs, batch_size=32) # One GPU call# Sequential (slow)for pair in pairs: score = model.predict([pair]) # Multiple GPU calls# Batched (fast)scores = model.predict(pairs, batch_size=32) # One GPU call3. Result Caching
from functools import lru_cacheimport hashlib<div></div>@lru_cache(maxsize=10000)def cached_score(query_hash: str, doc_hash: str) -> float: return cross_encoder.predict([(query, doc)])[0]<div></div># For common queries, this gives instant responsesfrom functools import lru_cacheimport hashlib@lru_cache(maxsize=10000)def cached_score(query_hash: str, doc_hash: str) -> float: return cross_encoder.predict([(query, doc)])[0]# For common queries, this gives instant responses4. Model Distillation Train a smaller student model on your cross-encoder's predictions:
-
Teacher:
ms-marco-MiniLM-L-12-v2(130MB, 12 layers) -
Student:
ms-marco-MiniLM-L-6-v2(90MB, 6 layers) -
Speed gain: ~40%, Accuracy loss: ~2-3%
Choosing the Right Model
Not all cross-encoders are created equal. Here's how to pick:
General-Purpose Models
ms-marco-MiniLM-L-6-v2 (Recommended for most use cases)
-
Size: 90MB
-
Speed: ~800ms for 100 pairs (CPU)
-
Trained on MS MARCO passage ranking
-
Good for: web search, general Q&A, documentation search
ms-marco-MiniLM-L-12-v2
-
Size: 130MB
-
Speed: ~1.2s for 100 pairs (CPU)
-
Better accuracy (+5% NDCG@10 on MS MARCO)
-
Good for: when accuracy matters more than latency
Domain-Specific Models
nli-deberta-v3-base (for entailment/contradiction)
-
Trained on NLI datasets
-
Good for: fact-checking, claim verification
-
Example: "Vitamin D prevents COVID" → Check against medical literature
stsb-roberta-base (for semantic similarity)
-
Trained on STS Benchmark
-
Good for: duplicate detection, paraphrase identification
-
Returns continuous similarity scores (0-5)
Multilingual Models
cross-encoder/mmarco-mMiniLMv2-L12-H384-v1
-
Supports 100+ languages
-
Trained on multilingual MS MARCO
-
Good for: international applications
Fine-Tuning for Your Domain
When to fine-tune:
-
You have 1000+ labeled query-document pairs
-
Domain-specific terminology (legal, medical, technical)
-
Unique ranking criteria (e.g., recency + relevance)
from sentence_transformers import CrossEncoderfrom sentence_transformers.cross_encoder.evaluation import CECorrelationEvaluatorfrom torch.utils.data import DataLoader<div></div># Prepare training data: (query, passage, label)train_samples = [ ("battery recycling safety", "thermal treatment required", 1), ("battery recycling safety", "solar panel efficiency", 0), # ... more examples]<div></div># Initialize base modelmodel = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2', num_labels=1)<div></div># Create DataLoadertrain_dataloader = DataLoader(train_samples, shuffle=True, batch_size=16)<div></div># Trainmodel.fit( train_dataloader=train_dataloader, epochs=3, warmup_steps=100, output_path='./fine-tuned-cross-encoder')from sentence_transformers import CrossEncoderfrom sentence_transformers.cross_encoder.evaluation import CECorrelationEvaluatorfrom torch.utils.data import DataLoader# Prepare training data: (query, passage, label)train_samples = [ ("battery recycling safety", "thermal treatment required", 1), ("battery recycling safety", "solar panel efficiency", 0), # ... more examples]# Initialize base modelmodel = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2', num_labels=1)# Create DataLoadertrain_dataloader = DataLoader(train_samples, shuffle=True, batch_size=16)# Trainmodel.fit( train_dataloader=train_dataloader, epochs=3, warmup_steps=100, output_path='./fine-tuned-cross-encoder')Real-World Pipeline Integration
RAG Systems
from langchain.retrievers import ContextualCompressionRetrieverfrom langchain.retrievers.document_compressors import CrossEncoderRerankerfrom langchain_community.vectorstores import FAISSfrom langchain_openai import OpenAIEmbeddings<div></div># Stage 1: Dense retrievalvectorstore = FAISS.from_documents(documents, OpenAIEmbeddings())base_retriever = vectorstore.as_retriever(search_kwargs={"k": 20})<div></div># Stage 2: Cross-encoder rerankingreranker = CrossEncoderReranker( model_name="cross-encoder/ms-marco-MiniLM-L-6-v2", top_n=5)<div></div>compression_retriever = ContextualCompressionRetriever( base_compressor=reranker, base_retriever=base_retriever)<div></div># Now your RAG gets the top 5 most relevant chunksquery = "How to prevent battery fires during recycling?"relevant_docs = compression_retriever.get_relevant_documents(query)from langchain.retrievers import ContextualCompressionRetrieverfrom langchain.retrievers.document_compressors import CrossEncoderRerankerfrom langchain_community.vectorstores import FAISSfrom langchain_openai import OpenAIEmbeddings# Stage 1: Dense retrievalvectorstore = FAISS.from_documents(documents, OpenAIEmbeddings())base_retriever = vectorstore.as_retriever(search_kwargs={"k": 20})# Stage 2: Cross-encoder rerankingreranker = CrossEncoderReranker( model_name="cross-encoder/ms-marco-MiniLM-L-6-v2", top_n=5)compression_retriever = ContextualCompressionRetriever( base_compressor=reranker, base_retriever=base_retriever)# Now your RAG gets the top 5 most relevant chunksquery = "How to prevent battery fires during recycling?"relevant_docs = compression_retriever.get_relevant_documents(query)E-commerce Search
class ProductSearchEngine: """Search engine for product catalogs with cross-encoder ranking.""" def __init__(self, products: List[Dict]): self.products = products self.cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2') def search(self, query: str, filters: Dict = None) -> List[Dict]: # Stage 1: Filter by category/price/availability candidates = self._apply_filters(self.products, filters) # Stage 2: BM25 keyword matching on titles + descriptions bm25_results = self._bm25_search(query, candidates, top_k=50) # Stage 3: Cross-encoder reranking texts = [f"{p['title']}. {p['description']}" for p in bm25_results] pairs = [(query, text) for text in texts] scores = self.cross_encoder.predict(pairs) # Add scores to products for product, score in zip(bm25_results, scores): product['relevance_score'] = float(score) # Sort and return bm25_results.sort(key=lambda x: x['relevance_score'], reverse=True) return bm25_results[:10]class ProductSearchEngine: """Search engine for product catalogs with cross-encoder ranking.""" def __init__(self, products: List[Dict]): self.products = products self.cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2') def search(self, query: str, filters: Dict = None) -> List[Dict]: # Stage 1: Filter by category/price/availability candidates = self._apply_filters(self.products, filters) # Stage 2: BM25 keyword matching on titles + descriptions bm25_results = self._bm25_search(query, candidates, top_k=50) # Stage 3: Cross-encoder reranking texts = [f"{p['title']}. {p['description']}" for p in bm25_results] pairs = [(query, text) for text in texts] scores = self.cross_encoder.predict(pairs) # Add scores to products for product, score in zip(bm25_results, scores): product['relevance_score'] = float(score) # Sort and return bm25_results.sort(key=lambda x: x['relevance_score'], reverse=True) return bm25_results[:10]Question Answering
def extractive_qa(question: str, context_passages: List[str]) -> str: """ Extract answer from most relevant passage using cross-encoder. """ # Rank passages model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2') pairs = [(question, passage) for passage in context_passages] scores = model.predict(pairs) # Get best passage best_idx = scores.argmax() best_passage = context_passages[best_idx] # Now run extractive QA on just this passage from transformers import pipeline qa_pipeline = pipeline("question-answering") answer = qa_pipeline(question=question, context=best_passage) return answer['answer']def extractive_qa(question: str, context_passages: List[str]) -> str: """ Extract answer from most relevant passage using cross-encoder. """ # Rank passages model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2') pairs = [(question, passage) for passage in context_passages] scores = model.predict(pairs) # Get best passage best_idx = scores.argmax() best_passage = context_passages[best_idx] # Now run extractive QA on just this passage from transformers import pipeline qa_pipeline = pipeline("question-answering") answer = qa_pipeline(question=question, context=best_passage) return answer['answer']When NOT to Use Cross-Encoders
Be honest about these limitations:
1. Initial Retrieval Over Large Corpora
Don't do this:
# 1 million documents, this will take hoursscores = cross_encoder.predict([(query, doc) for doc in million_docs])# 1 million documents, this will take hoursscores = cross_encoder.predict([(query, doc) for doc in million_docs])Do this:
# Retrieve 100 candidates firstcandidates = bi_encoder_search(query, top_k=100)# Then rerankscores = cross_encoder.predict([(query, doc) for doc in candidates])# Retrieve 100 candidates firstcandidates = bi_encoder_search(query, top_k=100)# Then rerankscores = cross_encoder.predict([(query, doc) for doc in candidates])2. Real-Time Search (<50ms latency requirement)
Cross-encoders add 100-800ms. If you need instant results, stick to bi-encoders or hybrid approaches without reranking.
3. Embedding-Based Clustering/Classification
Cross-encoders don't produce embeddings you can reuse. If you need document vectors for downstream tasks, use bi-encoders.
4. Highly Dynamic Corpora
If your document collection changes constantly (every minute), the reranking overhead might not be worth it. Consider caching strategies or faster models.
5. Resource-Constrained Environments
Raspberry Pi, edge devices, browsers—cross-encoders are too heavy. Use quantized bi-encoders instead.
Common Pitfalls and How to Avoid Them
1. Forgetting to Normalize Scores
# Wrong: Mixing unnormalized scoreshybrid_score = bm25_score + dense_score + cross_encoder_score<div></div># Right: Normalize firstdef min_max_normalize(scores): min_s, max_s = scores.min(), scores.max() return (scores - min_s) / (max_s - min_s + 1e-10)<div></div>hybrid_score = ( 0.3 * min_max_normalize(bm25_scores) + 0.3 * min_max_normalize(dense_scores) + 0.4 * min_max_normalize(cross_encoder_scores))# Wrong: Mixing unnormalized scoreshybrid_score = bm25_score + dense_score + cross_encoder_score# Right: Normalize firstdef min_max_normalize(scores): min_s, max_s = scores.min(), scores.max() return (scores - min_s) / (max_s - min_s + 1e-10)hybrid_score = ( 0.3 * min_max_normalize(bm25_scores) + 0.3 * min_max_normalize(dense_scores) + 0.4 * min_max_normalize(cross_encoder_scores))2. Not Handling Long Documents
Cross-encoders have token limits (usually 512):
from transformers import AutoTokenizer<div></div>def truncate_document(doc: str, max_tokens: int = 400) -> str: """Keep query + doc under 512 tokens.""" tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased') tokens = tokenizer.encode(doc, add_special_tokens=False) if len(tokens) > max_tokens: tokens = tokens[:max_tokens] return tokenizer.decode(tokens)<div></div># Use in pipelinetruncated = [truncate_document(doc) for doc in documents]scores = cross_encoder.predict([(query, doc) for doc in truncated])from transformers import AutoTokenizerdef truncate_document(doc: str, max_tokens: int = 400) -> str: """Keep query + doc under 512 tokens.""" tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased') tokens = tokenizer.encode(doc, add_special_tokens=False) if len(tokens) > max_tokens: tokens = tokens[:max_tokens] return tokenizer.decode(tokens)# Use in pipelinetruncated = [truncate_document(doc) for doc in documents]scores = cross_encoder.predict([(query, doc) for doc in truncated])3. Ignoring Batch Processing
# Slow: One pair at a timefor query, doc in pairs: score = model.predict([(query, doc)])[0] # 100 GPU calls<div></div># Fast: Batch everythingscores = model.predict(pairs, batch_size=32) # 4 GPU calls# Slow: One pair at a timefor query, doc in pairs: score = model.predict([(query, doc)])[0] # 100 GPU calls# Fast: Batch everythingscores = model.predict(pairs, batch_size=32) # 4 GPU calls4. Using Wrong Loss Function During Fine-Tuning
# For ranking (which doc is more relevant?)# Use: pairwise loss<div></div># For similarity scoring (how similar are these?)# Use: MSE or cosine loss<div></div># For classification (relevant/not relevant)# Use: cross-entropy# For ranking (which doc is more relevant?)# Use: pairwise loss# For similarity scoring (how similar are these?)# Use: MSE or cosine loss# For classification (relevant/not relevant)# Use: cross-entropyEvaluation Metrics That Actually Matter
Track these in production:
from sklearn.metrics import ndcg_scoreimport numpy as np<div></div>def evaluate_ranker(queries, ground_truth_rankings, predicted_rankings): """ queries: List[str] ground_truth_rankings: List[List[int]] # Relevance labels predicted_rankings: List[List[float]] # Predicted scores """ ndcg_scores = [] for gt, pred in zip(ground_truth_rankings, predicted_rankings): # NDCG@10 ndcg = ndcg_score([gt], [pred], k=10) ndcg_scores.append(ndcg) print(f"Mean NDCG@10: {np.mean(ndcg_scores):.4f}") print(f"Median NDCG@10: {np.median(ndcg_scores):.4f}") # Also track MRR (Mean Reciprocal Rank) mrr_scores = [] for gt in ground_truth_rankings: first_relevant = next((i+1 for i, label in enumerate(gt) if label > 0), None) if first_relevant: mrr_scores.append(1.0 / first_relevant) print(f"MRR: {np.mean(mrr_scores):.4f}")from sklearn.metrics import ndcg_scoreimport numpy as npdef evaluate_ranker(queries, ground_truth_rankings, predicted_rankings): """ queries: List[str] ground_truth_rankings: List[List[int]] # Relevance labels predicted_rankings: List[List[float]] # Predicted scores """ ndcg_scores = [] for gt, pred in zip(ground_truth_rankings, predicted_rankings): # NDCG@10 ndcg = ndcg_score([gt], [pred], k=10) ndcg_scores.append(ndcg) print(f"Mean NDCG@10: {np.mean(ndcg_scores):.4f}") print(f"Median NDCG@10: {np.median(ndcg_scores):.4f}") # Also track MRR (Mean Reciprocal Rank) mrr_scores = [] for gt in ground_truth_rankings: first_relevant = next((i+1 for i, label in enumerate(gt) if label > 0), None) if first_relevant: mrr_scores.append(1.0 / first_relevant) print(f"MRR: {np.mean(mrr_scores):.4f}")Production Checklist
Before deploying cross-encoders:
-
[ ] Measured latency with your actual corpus size and top-k settings
-
[ ] Set up monitoring for P95/P99 latency and throughput
-
[ ] Implemented caching for common queries
-
[ ] Added fallback to bi-encoder-only mode if reranking times out
-
[ ] Tested on edge cases (very long documents, unusual queries)
-
[ ] Benchmarked offline with NDCG/MRR on labeled test set
-
[ ] Configured batching for optimal GPU utilization
-
[ ] Set up A/B testing to measure impact on user engagement
-
[ ] Documented model version and training data for reproducibility
Conclusion
Cross-encoders are precision instruments, not Swiss Army knives. They excel at one thing: telling you which of your candidate documents truly answers the query.
Use them as the final reranking stage after fast retrieval. Don't use them for initial search over millions of documents. Monitor their latency impact. Cache aggressively.
When accuracy is critical—medical Q&A, legal research, technical support—the 100-200ms latency penalty is worth it. Your users won't notice the extra 200ms, but they will notice when the right answer is always in the top 3 results.
Further Reading
Official Documentation:
Research Papers:
-
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
-
ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction
Related Articles on This Blog:
Have questions about implementing cross-encoders in your production system? Drop a comment below.
Related Articles
- Agent Building Blocks: Build Production-Ready AI Agents with LangChain | Complete Developer Guide
- ChatML Guide: Master Structured Prompts for LLMs
Follow for more technical deep dives on AI/ML systems, production engineering, and building real-world applications: